相关工具说明
- 数据抽取层
- sqoop(结构化关系型数据抽取)、flume(非结构化日志接入)
- 数据存储层
- hadoop-hdfs、kafka(流式总线)
- 计算调度层
- 离线计算:hive、spark、MR、tez
- 实时计算:storm、spark、近年来flink也较多
- 数据调度:Airflow Azkaban Oozie等、Dolphin-scheduler
- 查询引擎层:ROLAP、MOLAP以及二者混搭
- Hbase
- ES
- Apache Kylin
- Apache Druid
- TiDB
- Impala
- ClickHouse
- Presto
- http://www.360doc.com/content/20/0815/19/22849536_930520678.shtml
- Hawq
- Spark SQL
- Greenplum
- HANA
- 数据可视化层
- 基础框架:ECharts、D3、Three.js
- 商业:Tableau、DataV、FineReport、FineBI、PowerBI(微软)
- 开源:Bokeh、Matplotlib、Metabase、Superset
- Superset:SQL语句、图表、Dashbord、权限
- Redash: 基于python
- Metabase:基于java、有收费版。https://zhuanlan.zhihu.com/p/52085283 (缺点较多)
- Saiku
相关架构图
- https://img-blog.csdnimg.cn/img_convert/a82b7d72897ab899cdb8f9c21f354c45.png
- https://img-blog.csdnimg.cn/img_convert/2abe208f7e8fdd26db42f0e5155746fb.png
相关文档
- 数据中台的核心组成以及一些技术选型参考 https://blog.51cto.com/u_14410880/2546005
Flume
Flume简介
- Apache Flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具
- 官网、v1.9中文文档
- 相关概念
- Event是Flume定义的一个数据流传输的最小单元
- Agent就是一个Flume的实例,本质是一个JVM进程,该JVM进程控制Event数据流从外部日志生产者那里传输到目的地(或者是下一个Agent)
- 当Source接收Event时,它将其存储到一个或多个channel。该channel是一个被动存储器(或者说叫存储池),可以存储Event直到它被Sink消耗
- Flume支持以下比较流行的日志类型读取:Avro(Apache Avro)、Thrift、Syslog、Netcat
数据流模型
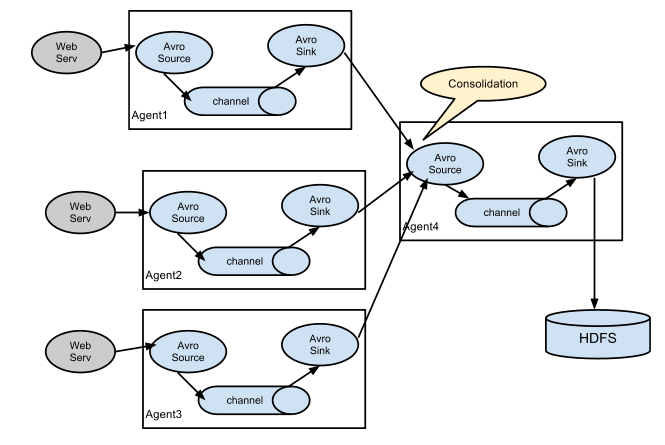
- 次数据流只是一种组合方式,简单的只需要一个Agent,甚至还有更复杂的组合
- 结合HDFS使用参考bigdata-project-user-analysis.md#Flume传输日志
Flume安装
1 | cd /opt/bigdata/ |
单Agent测试
- 配置文件(~/flume/test.conf)
1 | # Name the components on this agent 名称和后面对应,其中a1为当前Agent名称, |
- 启动并测试
1 | # node01启动,指定Agent的名称为 a1 |
两个Agent连接测试
- node02配置文件(~/flume/test2.conf)
1 | # Name the components on this agent |
- node01配置文件(~/flume/test2.conf)
1 | # Name the components on this agent |
- 启动
1 | # 启动 node01/node02 |
sqoop
可视化框架
Superset
- 官网
- 由Airbnb开源的、目前由Apache孵化的,基于Flask-appbuilder搭建,基于python实现
- 功能
- 自带SQLite数据库并支持连接Hive、Impala、MySql、Oracle等几乎所有主流的数据源
- 支持和弦图、事件流图、热力图、视图表等及其它常规的可视化展示图表
- 支持可控的数据展示,能自定义展示字段、数据源等
- 支持权限控制
- 内含SQL查询面板模块
- 创建和分享dashboard
- 参考文章
