书籍推荐
- 计算机:《编码:隐匿在计算机软硬件背后的语言》《深入理解计算机系统》
- 语言:C JAVA 《C 程序设计语言》《C Primer Plus》
- 数据结构与算法:《Java 数据结构与算法》《算法》《算法导论》《计算机程序设计艺术》
- 操作系统:Linux 内核源码解析、Linux 内核设计与实现、30 天自制操作系统、深入理解 linux 内核、深入理解计算机系统
- 网络:机工《TCP/IP 详解》卷一
- 编译原理:《编译原理》《编程语言实现模式》
- 数据库:SQLite 源码、Derby(JDK 自带数据库)
硬件基础知识
计算机的组成
CPU 制作
- Intel cpu 的制作过程:https://haokan.baidu.com/v?vid=11928468945249380709&pd=bjh&fr=bjhauthor&type=video
- CPU 是如何制作的(文字描述):https://www.sohu.com/a/255397866_468626
- CPU 的原理
- 计算机需要解决的最根本问题:如何代表数字
- 晶体管是如何工作的:https://haokan.baidu.com/v?vid=16026741635006191272&pd=bjh&fr=bjhauthor&type=video
- 晶体管的工作原理:https://www.bilibili.com/video/av47388949?p=2
- 发展过程
- 硅 - 加入特殊元素 - P 半导体 N 半导体 - PN 结 - 二极管 - 场效应晶体管 - 逻辑开关
- 基于逻辑开关实现:与门、或门、非门(异或),即基础逻辑电路
- 再实现加法器、累加器、锁存器
- 实现手动计算(通电一次,运行一次位运算)
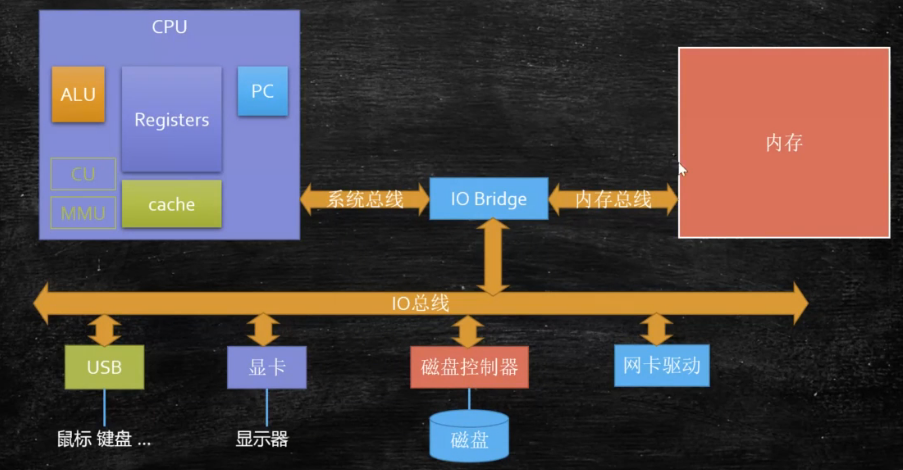
- 加入内存,实现自动运算(每次读取内存指令)。CPU 的每个针脚可以读取一个 0/1
- CPU、内存、显卡等都是和主板进行连通
- 总线
- 总线是计算机各部件之间传递信息的基本通道,将每根小线捆到一起的一根线即为总线
- 依据传递的内容不同,总线又分为数据总线、地址总线、控制总线 3 种。CPU 根据不同总线过来的从内存读取数据,从而区分哪些为立即数,哪些为指令(最终还是 0101,因此需要根据总线类型区分)
- 汇编语言(机器语言)的执行过程
- 最早手工输入:纸带计算机,纸带上有孔,有孔没孔可代表 1/0。一次一只虫子堵住了此孔,因此产生了 BUG
- 汇编语言的本质:机器语言(0101)的助记符(mod),其实它就是机器语言
- 计算机通电 -> CPU 读取内存中程序(电信号输入)-> 时钟发生器不断震荡通断电(相关的如 CPU 频率) -> 推动 CPU 内部一步一步执行(执行多少步取决于指令需要的时钟周期)-> 计算完成 -> 写回(电信号)-> 写给显卡输出(sout,或者图形)
- c 编译完后直接是机器码,CPU 可直接执行,即编译执行;java 编译后是二进制码(ByteCode),执行时通过虚拟机解释成机器语言进行执行,即解释执行
- 量子计算机
- 量子比特,可同时表示 1 和 0
- 潘建伟 18bit 量子纠缠:使用 6 个光子(有 3 个特点:路径、偏振、角动力)得到 6*3=18 个 bit,每个 bit 有 2 中状态,相当于 2^18 中可能。经典计算机只能表示 2^18 中的一个数,而量子计算则能同时表示 2^18 个数
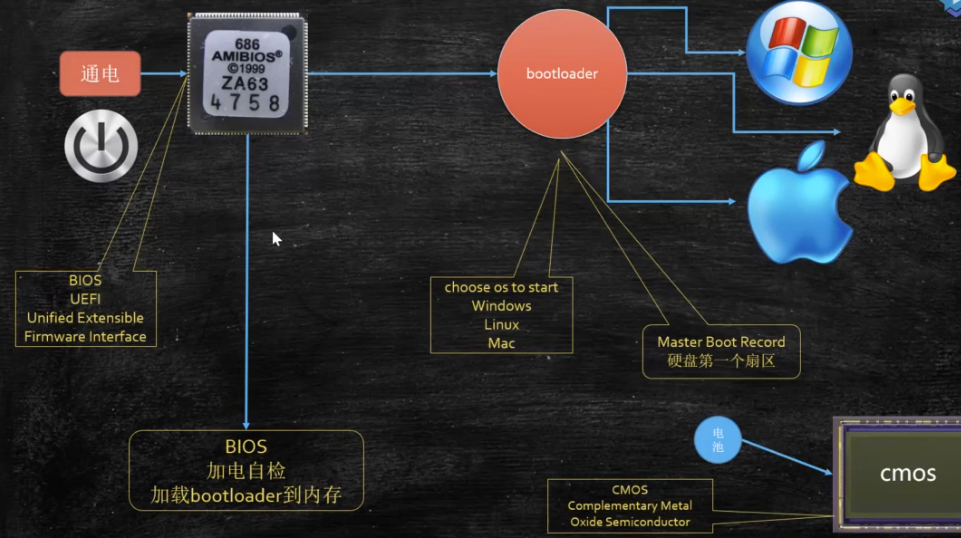
启动
通电 -> bios/uefi 工作 -> 自检 -> 到硬盘固定位置加载 bootloader -> 读取可配置信息 -> CMOS(如保存开机密码,有一块额外的小电池通电,没电了数据就会丢失)
常见指标
- 磁盘寻址是ms级,带宽是G、M
- 固态硬盘IO速度约500M/S,机械硬盘约是100M/S,网卡IO约是100M/S(ping返回的单位基本是ms)
- 磁盘扇区大小一般是512Byte,此时获取数据成本较高,因此无论读取数据多少,操作系统每次都是从磁盘中拿4K的数据
- 内存寻址是ns级,带宽很大;磁盘比内存寻址慢了10w倍
- 计算机的2个基础设施
- 冯诺依曼体系的硬件
- 以太网,tcp/ip的网络
CPU
CPU 的基本组成
- PC(Program Counter) 程序计数器(记录当前指令地址)
- Registers 寄存器,暂时存储 CPU 计算需要用到的数据,速度比内存快很多
- Intel 的寄存器如:AX/BX…(16 位),EAX/EBX…(32 位),RAX/RBX…(64 位)
- 64 位机器(CPU)一般指寄存器一次性可以存储 64 位,ALU 一次性也可读取 64 位
- ALU(Arithmetic & Logic Unit) 运算单元。如从寄存器的 AX 中读取 2,BX 中读取 3,然后通过 ALU 进行运算得到 5,并将 5 存储在如 DX 中,最后写回内存
- CU(Control Unit) 控制单元
- 由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)三个部件组成
- MMU(Memory Management Unit) 内存管理单元
- Cache 缓存(L1/L2/L3三级缓存,速度介于寄存器和内存之间)
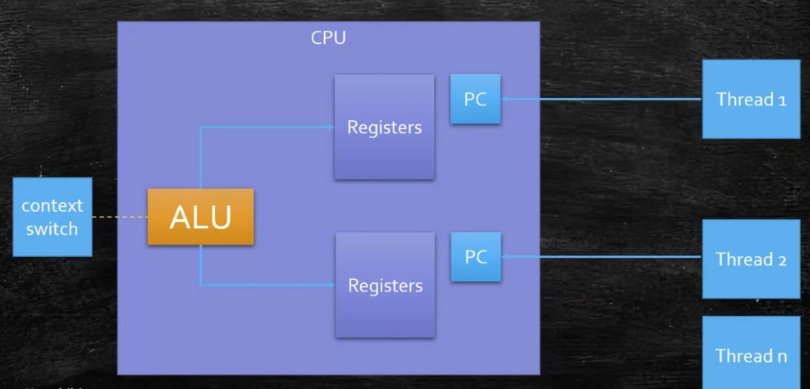
超线程
一个 ALU 对应多个 PC 和 Registers,即所谓的 4 核 8 线程,一个核如下
三级缓存和伪共享
- 三级缓存和伪共享
- 按块读取
- 从硬盘往内存读,从内存往缓存读都是按块读取的,从而提高效率。充分发挥总线、CPU 针脚一次性读取更多数据的能力
三级缓存
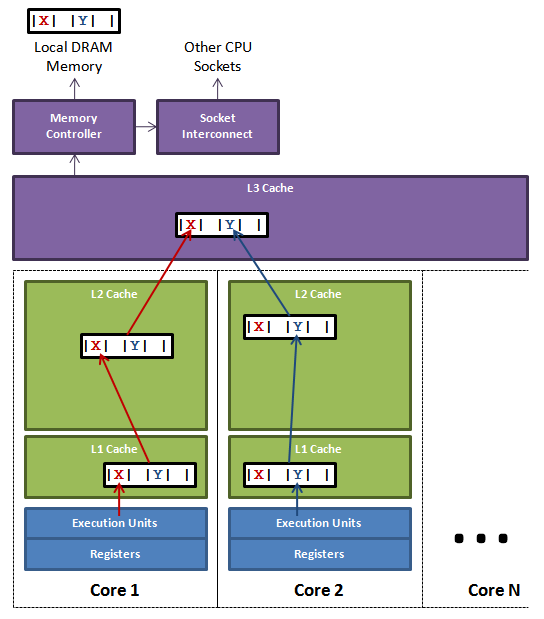
- CPU 缓存可以分为一级缓存(L1),二级缓存(L2),部分高端 CPU 还具有三级缓存(L3)
- 每一级缓存中所储存的全部数据都是下一级缓存的一部分,越靠近 CPU 的缓存越快也越小,所以 L1 缓存很小但很快
- L1,L2 只能被单独的 CPU 核使用
- L3 被单个插槽上的所有 CPU 核共享
- 主存(常说的内存)则由全部插槽上的所有 CPU 核共享
- 每个核都有自己私有的 L1,、L2 缓存。那么多线程编程时,另外一个核的线程想要访问当前核内 L1、L2 缓存行的数据,该怎么办呢?
- 有人说可以通过第 2 个核直接访问第 1 个核的缓存行,这是当然是可行的,但这种方法不够快。跨核访问需要通过 Memory Controller(内存控制器,是计算机系统内部控制内存并且通过内存控制器使内存与 CPU 之间交换数据的重要组成部分),典型的情况是第 2 个核经常访问第 1 个核的这条数据,那么每次都有跨核的消耗。更糟的情况是,有可能第 2 个核与第 1 个核不在一个插槽内,况且 Memory Controller 的总线带宽是有限的,扛不住这么多数据传输
- 所以,CPU 设计者们更偏向于另一种办法: 如果第 2 个核需要这份数据,由第 1 个核直接把数据内容发过去,数据只需要传一次
- 由此,第 2 个核修改了这份数据,那么第 1 个核原来的数据就成了脏数据,解决方式就是通过 EMSI 协议进行缓存行操作(见下文)
- CPU 缓存可以分为一级缓存(L1),二级缓存(L2),部分高端 CPU 还具有三级缓存(L3)
- 伪共享
- 缓存系统中是以缓存行(cache line, 通常是 64 字节)为单位存储的,当多线程修改互相独立的变量时(发起的 RFO 请求会耗性能),如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享
- 解决伪共享
- JDK7 中很多采用缓存行填充(空间换时间)。Disruptor 就是通过缓存行填充实现,参考concurrence.md#Disruptor
- JDK8 开始可以使用@Contended 注解(需加 JVM 参数:-XX:-RestrictContended)来避免伪共享
- 缓存行对齐(缓存行填充)
- 对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存航对齐的编程方式
MESI协议及RFO请求
- 现代CPU的数据一致性实现通过缓存锁(MESI …) + 总线锁(老的CPU直接通过锁总线,L2连接L3时的总线)
- MESI(M 修改, E 专有, S 共享, I 无效)、MSI、MOSI 及 Dragon Protocol 等都是为了解决缓存一致性的协议
- MESI主要是Inter处理一致性的解决方法
- RFO(Request For Owner)请求,为 MESI 协议中需要将当前核心的某缓存行设置为 E,将其他核心的该缓存行设置为 I
WC 合并写技术
- WC(Write Combining) 合并写
- 某些计算机在寄存器和三级缓存之间还有其他缓存,如与 L1 之间有 Load Buffer、Store Buffer,与 L2 之间有 WC Buffer,他们的空间很小,但是速度比三级缓存快
- 由于 ALU 速度太快,所以在写入 L1 的同时写入一个 WC Buffer,满了之后,再直接更新到 L2(因为 L1 最终需要写入到 L2),大小一般是 4 个字节
WC合并写技术程序证明
1 | // runCaseTwo比runCaseOne更快(但是runCaseTwo循环次数更多,且写入的数据多) |
乱序执行与防止指令重排
- 乱序执行
- CPU 执行命令时并不一定完全按照程序代码一行行的执行,而会进行指令重排,当 CPU 在进行读等待的同时执行指令,最终结果不会有影响。CPU 乱序的是为了提高效率
- as-if-serial:不管如何重排序,单线程执行的结果不变,看上去像是 serial
- 程序证明:jvm/jmm/Disorder.java
- 禁止乱序
- CPU 层面
- 使用内存屏障或锁总线
- 如 Intel 底层使用内存屏障,对应原语(lfence 读屏障 sfence 写屏障 mfence 混合屏障)。sfence 表示:在某个 sfence 指令之前的写指令为 A 指令集,在其后的写指令为 B 指令集,此时 A 指令必须在 B 指令之前完成
- 如 Intel lock 汇编指令,执行后会锁住内存子系统来确保执行顺序,甚至跨多个 CPU
- lock 指令一般 CPU 都有,但是内存屏障可能部分品牌没有内存屏障原语支持,HotSpot 直接使用了 lock 指令来防止指令重排
- 使用内存屏障或锁总线
- JVM 层级
- JSR(JVM 规范)内存屏障(LL LS SL SS)
- LoadLoad(LL):对于 Load1;LoadLoad;Load2;这样的指令,Load2 即之后读操作要在 Load1 读操作之后完成。其他如 LoadStore 类似
- volatile禁止指令重排即使用了内存屏障,参考concurrence.md#volatile
- JSR(JVM 规范)内存屏障(LL LS SL SS)
- CPU 层面
- JVM 规定重排序必须遵守 8 个 hanppens-before 原则
- 案例:DCL 单例(双重检查单例,Double Check Lock)必须配合 volatile,此时 volatile 即达到了指令重排的作用
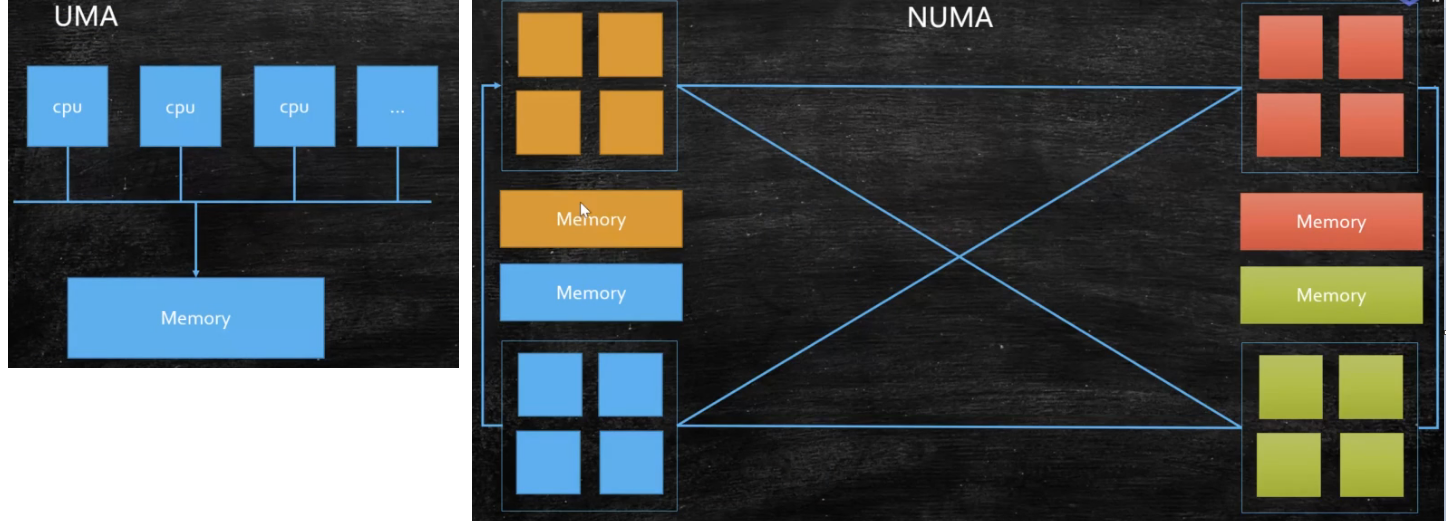
NUMA
- UMA(Uniform Memory Access):多个 CPU 通过一个总线访问同一个内存。但缺点是 CPU 增加导致资源抢占,工业测试证明 4 颗效果最好
- NUMA(Non Uniform Memory Access):非同一内存访问
- ZGC - NUMA aware:分配内存会优先分配该线程所在 CPU 的最近内存
OS
内核
- kernel 内核作用:负责调度 CPU,管理内存、文件系统、进度调度、设备驱动等
- 内核分类
- 宏内核:PC、phone
- 微内核:弹性部署、5G、IoT。用户请求某个内核,这个内核可能无法处理,他会请求其他内核进行处理(也可能联网请求,如控制冰箱内核、电视内核等)
- 外核:为应用定制操作系统,科研中(多租户 request-based GC JVM)
- 内核态与用户态
- cpu 分不同的指令级别:0 1 2 3
- linux 内核跑在 ring 0 级,用户程序跑在 ring 3,对于系统的关键访问(如访问硬件),需要经过 kernel 的同意,保证系统健壮性
- 内核执行的操作:200 多个系统调用,sendfile read write pthread fork 等
- 站在 OS 老大的角度,JVM 就是个普通程序
进程/线程/纤程
- 进程和线程
- 进程是 OS 分配资源的基本单位,线程是执行调度的基本单位
- 某个进程获的CPU执行时间,此时可能执行此进程下的不同线程,直到此进程失去CPU执行时间
- 一个进程可以包括多个线程
- 每个进程都有独立的代码和数据空间(程序上下文),进程之间切换开销大(需要保存和恢复上下文);线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
- 进程是 OS 分配资源的基本单位,一个进程的内存空间是共享的,每个线程都可以使用这些共享内存
- 进程是 OS 分配资源的基本单位,线程是执行调度的基本单位
- 纤程
- 用户态的线程,线程中的线程,切换和调度不需要经过 OS。java 的 new Thread 与 OS 系统的线程一一对应
- 优势
- 切换和调度不需要和内核打交道。如线程要和内核打交道,因此中途会调用 80 软中断(见下文),效率会低
- 占有资源很少,OS 启动一个线程大约要 1M 空间,启动一个 Fiber 纤程大约需要 4K
- 纤程切换比较简单,线程切换较耗时。可以启动很多个 10W+,OS 启动 1W 个线程时进行切换就会较耗时
- 目前支持内置纤程的语言:Kotlin、Scala、Go、Python(lib)… Java(需要 open jdk 的 loom 库支持)
- 进程在 linux 中也称 task,是系统分配资源的基本单位
- 资源:独立的地址空间、内核数据结构(进程描述符等)、全局变量、数据段等
- 进程描述符:PCB(Process Control Block)
- 进程创建和启动
- 系统函数 fork() exec()
- 从 A 中 fork B 的话,A 称之为 B 的父进程
- 僵尸进程
- 父进程产生子进程后,会维护子进程的一个 PCB 结构,子进程退出,由父进程释放;如果父进程没有释放,那么子进程成为一个僵尸进程
ps -ef | grep defunct查询所有的僵尸进程,此时只能杀掉父进程才会从 ps 中消失
- 孤儿进程
- 子进程结束之前,父进程已经退出,孤儿进程会成为 init 进程的孩子,由 1 号进程进行维护
僵尸进程和孤儿进程案例
1 | // 僵尸进程 |
- 进程类型
- IO 密集型:大部分时间用于等待 IO
- CPU 密集型:大部分时间用于计算
- 进程(任务)调度
- 发展过程为从单任务独占到多任务分时,最大限度的压榨 CPU 资源
- 多任务的抢占式和非抢占式
- 非抢占式(cooperative multitasking):除非进程主动让出 cpu(yielding),否则一直运行
- 抢占式(preemptive multitasking,采用较多):由进程调度器强制开始或暂停(抢占)某一进程的执行
- linux 普通进程调度
- linux2.5 采用经典 Unix O(1)调度策略(执行时间均匀分配),偏向服务器,但对 UI 交互不友好
- linux2.6.23 采用
CFS(Completely Fair Scheduler) 完全公平调度算法- 按优先级分配时间片的比例,记录每个进程的执行时间,如果有一个进程执行时间少于他应该分配的比例,则优先执行
- 进程优先级
- 实时进程 > 普通进程(0 -> 99)
- 普通进程则按照 nice 值(-20 -> 19)
- linux 默认调度策略
- 实时进程:使用SCHED_FIFO(按照优先级来)和SCHED_RR(优先级一样则轮询)两种
- 普通进程:使用CFS
- 默认执行等级为 FIFO 的实时进程,且 linux 会一致执行它,除非自己让出 CPU、更高等级的 FIFO、同 FIFO 等级的 RR 抢占它。只有实时进程主动让出或者执行完毕,普通进程才有机会执行
- 进程间通信方式。参考:https://blog.csdn.net/qq_39507723/article/details/97811048
- 共享内存通信(配合信号量实现同步)
- 管道通信:半双工的通信方式,数据只能单向流动
- 消息队列通信:克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点
- 套接字(socket)通信:可用于不同机器间的进程通信
Copy-On-Write写时复制
Copy-on-write,简称COW,写时复制。是一种计算机程序设计领域的优化策略- Linux的COW
- fork创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程,这样创建子进程的速度就很快了!(不用复制,直接引用父进程的物理空间) ^1
- 实现原理
- fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份给调用者(修改者),其余的页还是共享父进程的
- 修改时才会复制,只会复制异常页,而不是整个共享内存
- 如linux的管道符就是基于fork()完成,具体参考特殊符号-管道符
|
- 特点
- COW技术可减少分配和复制大量资源时带来的瞬间延时
- COW技术可减少不必要的资源分配。比如fork进程时,并不是所有的页面都需要复制
- 缺点:如果在fork()之后,父子进程都还需要继续进行大量写操作,那么会产生大量的分页错误(页异常中断page-fault)
- Redis的COW(基于linux的COW)
- Redis在持久化时,如果是采用bgsave命令或者bgrewriteaof的方式,那Redis会fork出一个子进程来读取数据,从而写到磁盘中
- 总体来看,Redis还是读操作比较多。如果子进程存在期间,发生了大量的写操作,那可能就会出现很多的分页错误(页异常中断page-fault),这样就得耗费不少性能在复制上
- 而在rehash阶段上,写操作是无法避免的。所以Redis在fork出子进程之后,将负载因子阈值提高,尽量减少写操作,避免不必要的内存写入操作,最大限度地节约内存
Java的COW(和linux的COW无关)^2
- CopyOnWriteArrayList
- CopyOnWriteArraySet
源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// 只截取了部分 CopyOnWriteArrayList 代码片段
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}- 说明
- COWList 读操作是无锁的
- COWList 写与写之间是互斥的
- 底层持有的数组变量 array 是通过 volatile 修饰的
- 说明
中断
- 中断为硬件或软件要和内核打交道的处理信号。硬件像磁盘,网卡,键盘,时钟等;软中断如80中断
- 在微机系统中,对于外部中断,中断请求信号是由外部设备产生,并施加到CPU的NMI或INTR引脚上,CPU通过不断地检测NMI和INTR引脚信号来识 别是否有中断请求发生。对于内部中断,中断请求方式不需要外部施加信号激发,而是通过内部中断控制逻辑去调用
- 中断处理过程
- 请求中断
- 响应中断
- 关闭中断(CPU不再响应其他中断)
- 保留断点
- 中断源识别
- 保护现场(将断点处各寄存器的内容压入堆栈保护起来)
- 中断服务子程序
- 恢复现场(指令将保存在堆栈中的各个寄存器的内容弹出,即恢复主程序断点处寄存器的原值)
- 中断返回
- 中断向量表:0-255号,每一个对应一个处理程序,中断时需要据此判断执行的中断处理程序。记录如键盘对应的处理程序,鼠标对应的处理程序等,其中128(0x80)即为软中断
- 软中断
- 又称 80 中断/系统调用,指软件产生的中断,即用户空间的处理程序需要调用内核空间的函数,应该尽量避免出现软中断(中断处理过程较长)
- 软中断方式:int 0x80(80 中断,interrupt 128) 或者 sysenter 原语(更先进)
- 调用过程:通过 ax 寄存器填入系统调用号(内核函数的编号),参数通过 bx cx dx si di 传入内核,返回值写到 ax 进行返回
- 如 java 读网络的中断过程:jvm read() - c 库 read() - 内核空间 - system_call()系统调用处理程序 - sys_read()
- 可使用
strace查看程序的系统调用情况 - 基于汇编理解软中断
yum install nasm搭建汇编环境- 编译
nasm -f elf hello.asm -o hello.o - 链接
ld -m elf_i386 -o hello hello.o生成一个 hello 可执行文件 - 执行
./hello
1 | ;hello.asm |
- 一个程序的执行过程,要么处于用户态,要么处于内核态(调用了软中断)
内存管理
- 内存管理的发展历程
- DOS 时代:同一时间只能有一个进程在运行(也有一些特殊算法可以支持多进程)。内存大概 64K 数量级
- windows9x(windows95 等):多个进程装入内存,内存大概 16M 数量级。产生了问题:内存不够用、互相打扰
- 为了解决上述两个问题,诞生了现在的内存管理系统:分页装入、虚拟地址、软硬件结合寻址
分页装入、虚拟地址、软硬件结合寻址
- 分页装入(解决内存不够用)
- 内存中分成固定大小的页框(大小固定为 4K),且程序(硬盘上)也分成 4K 大小的块,用到哪一块,加载那一块到内存的页框中(即Page Cache)。加载的过程中,如果内存已经满了,会把最不常用的一块放到 swap 分区,把最新的一块加载进来,这个就是著名的LRU(Least Recently Used)算法(见[msb#一#161#00:58:13])
- Page Cache
- Page Cache以Page为单位(大小一般为4K,64位系统为8K),缓存文件内容,存在于内核空间(只要内存空间有空余就可以存放Page Cache)。缓存在Page Cache中的文件数据,能够更快的被用户读写
- 从硬盘读取文件时,先拷贝到内核的Page Cache,并将FD文件描述符相关信息保存在用户程序内存,用户程序通过FD访问该文件
- 如果两个进程读取一个文件,则此文件在磁盘的 Page Cache 是一个,只是每个进程的文件描述符(如记录了各自的该文件读写位置)不同
- 在第一次加载文件Page到内存时涉及到磁盘操作,相对较慢,之后再次访问此Page Cache相当于访问内存,速度回很快。如果访问的数据所在Page没有加载到内存,则会产生缺页中断,会将缺失的加载到磁盘;如果内存空间不足,会将不经常访问的放到Swap空间
- 缺页中断:需要用到页面内存中没有,产生缺页异常(中断),由内核处理并从磁盘加载到内存
- 写入到内核Page Cache的pages成为脏页,稍后会由内核线程pdflush真正写入到硬盘上
- 脏页(Dirty Pages)
- 程序创建和修改文件则默认会有一个脏标识,直到内存使用超过设置阈值(如 10%)则会一次性将脏标识的数据刷到磁盘,并去掉脏标识。此时可能并不会从内存中移除,知道内存不足才会将未使用的Page Cache移出
- 脏页写回磁盘方法
- 手动调用sync()或者fsync()系统调用把脏页写回
sync函数只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync函数fsync函数只对由文件描述符filedes指定的单一文件起作用,并且等待写磁盘操作结束,然后返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性
- pdflush进程会定时把脏页写回到磁盘
- 手动调用sync()或者fsync()系统调用把脏页写回
- 脏页不能被置换出内存,如果脏页正在被写回,那么会被设置写回标记,这时候该页就被上锁,其他写请求被阻塞直到锁释放
- 脏页(Dirty Pages)
- 读写Page Cache是要经过内核的,从而会产生系统调用(80中断)。如Java的带Buffer写会先将数据存放在jvm(用户空间内存)中,然后一次性提交给内核,此时产生的系统调用少,因此效率高
- 缺点:容易丢数据
- 数据会先写在 Page Cache 中,linux 根据配置,当占用一定内存大小才会将内存中脏页数据刷新到磁盘,如果此时突然断电则会丢失没来得及写入到磁盘的数据(如果正常关机则没事)
- Buffer Cache
- Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,Page cache中的数据交给Buffer Cache
- Page cache用来缓存文件数据,Buffer Cache用来缓存磁盘(块)数据。在有文件系统的情况下,对文件操作,那么数据会缓存到Page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到Buffer Cache
- 2.6内核中的Buffer Cache和Page cache在处理上是保持一致的,但是存在概念上的差别,page cache针对文件的cache,buffer是针对磁盘块数据的cache
- cache是解决cpu与内存间的速度不对等问题,buffer是解决内存与磁盘间的速度不对等问题
虚拟内存(解决相互打扰问题)
- DOS Win31 等,各进程间内存可互相访问,容易相互影响
- 虚拟内存让进程工作在虚拟空间,程序中用到的空间地址不再是直接的物理地址,而是虚拟的地址,这样,A 进程永远不可能访问到 B 进程的空间
- 虚拟空间大小为寻址空间大小,64 位系统为 2^64 byte,比物理空间大很多
计算机虚拟内存

- 进程内部分段(格式固定),段内部分页。需要该页的时候加载到物理内存的 page cache 中
- 站在进程的角度,好像是进程独占了内存和 CPU,上图中虚拟内存中含是一个映射的内核
- 共享库如汇编中调用 C 语言的一些函数,如 read、print 等函数库
- 内存映射
- 逻辑地址(偏移量) + 段的基地址 = 线性地址(虚拟空间地址)
- 线性地址再通过 OS + MMU(Memory Management Unit,放在 CPU 中)硬件映射为物理地址。此时只有 OS 知道物理的地址,因此相对安全
- 软硬件结合寻址
- 原本内存和外部设备(如磁盘等 IO 设备)的交互必须经过 CPU(的寄存器),如由 CPU 通过总线将磁盘的数据加载到内存
- 后来增加了DMA(Direct Memory Access,协处理器)设备,可直接让外部设备直接和内存进行交互。此时可提供读写效率,且不浪费 CPU
内核同步机制
- 基本概念
- 临界区(critical area):访问或操作共享数据的代码段。简单理解:synchronized 大括号中部分(原子性)
- 竞争条件(race conditions)两个线程同时拥有临界区的执行权
- 数据不一致:data unconsistency 由竞争条件引起的数据破坏
- 同步(synchronization)避免 race conditions
- 锁:完成同步的手段(门锁,门后是临界区,只允许一个线程存在)。上锁解锁必须具备原子性
- 原子性(象原子一样不可分割的操作)
- 有序性(禁止指令重排)
- 可见性(一个线程内的修改,另一个线程可见)
- 内核同步常用方法
- 原子操作 – 内核中类似于 java 的 AtomicXXX(基于 cas,但是内核的原子操作是基于原语完成的),位于
linux/types.h - 自旋锁 – 内核中通过汇编支持的 cas,位于
asm/spinlock.h - 读-写自旋 – 类似于 ReadWriteLock,可同时读,只能一个写。读的时候是共享锁,写的时候是排他锁
- 信号量 – 类似于 Semaphore(PV 操作 down up 操作 占有和释放)。重量级锁,线程会进入 wait(Java 的 Semaphore 是通过 cas 完成),适合长时间持有的锁情况
- 读-写信号量 – downread upread downwrite upwrite(多个写,可以分段写,比较少用)分段锁
- 互斥体(mutex) – 特殊的信号量(二值信号量),类似 synchronized
- 完成变量 – 特殊的信号量(A 发出信号给 B,B 等待在完成变量上)。vfork() 在子进程结束时通过完成变量叫醒父进程,类似于(Latch)
- BKL:大内核锁(早期,现在已经不用)
- 顺序锁(内核 v2.6 开始) – 线程可以挂起的读写自旋锁,基于序列计数器:从 0 开始,写时+1,写完释放+1;读前发现单数,说明有写线程,可进行等待或读取临时值;读前为偶数,说明已经写完,可进行读取;读前读后序列一样,说明没有写线程打断
- 禁止抢占 – preempt_disable()
- 内存屏障 – 见乱序执行与防止指令重排
- 原子操作 – 内核中类似于 java 的 AtomicXXX(基于 cas,但是内核的原子操作是基于原语完成的),位于
IO
文件
- 一#166
- VFS(虚拟文件系统)
- Kernel 内部模块,为一颗目录树,每个节点可以找一个物理位置或网络接口,每个物理位置可以是不同的文件系统,如 FAT、EXT4。而 windows 看到的 C 盘/D 盘为物理文件系统
- inode 号
- 文件打开后的唯一 id 号。读文件时:一般先访问内核 - 打开目标文件 - inode 号被加载 - 加载元数据 - 内核读取数据到内存(在内存中开启一个 4k 大小的 page cache)
stat test.txt可查看到文件的 inode 号
- FD(File Descriptor)文件描述符
- 如果两个进程读取同一个文件,则 inode 号相同,只是各自的文件描述符(FD)不同。如一个读取到 A 位置,指针偏移量为 seek 5;另一个读取到 B 位置,指针偏移量为 seek 11
- 当 o = new OutputStream(…)时在操作系统就会产生一个 fd,可理解为把 fd 的引用赋值给 o
- darty 脏页
- page cache 被修改后会有一个 darty 标识,而 flush 到磁盘有不同的策略,如:程序手动控制,或者交由内核自动刷到磁盘
- 文件类型,常见如
-普通文件(可执行,图片,文本),type=REGd目录,type=DIRl链接,包括硬链接、软连接(修改其中一个文件,另外一个文件会自动变化)b块设备。可以自制一个镜像,里面放入可执行程序,然后拷贝到其他地方进行使用c字符设备,如标准输入输出,type=CHRssocketppipeline[eventpoll]
- 示例
文件操作示例
1 | ## 链接 |
io/nio
- 一#174
ByteBuffer指针移动图
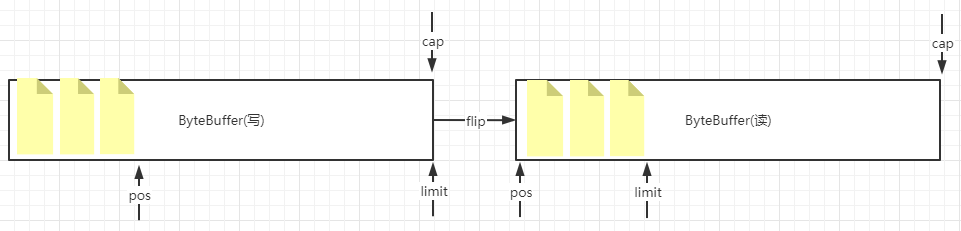
- 如(allocate堆内/allocateDirect堆外)分配一个cap容量为1024自己的ByteBuffer,此时position为0,limit为1024,capacity为1024
- 写入3个字节后,pos为3
- 然后flip: 翻转读和写(切换读写模式),此时变为读模式,limit为变成3(防止读超了)
- 然后读取2个字节后,pos为2
nio包中的ByteBuffer和FileChannel.map的读写过程
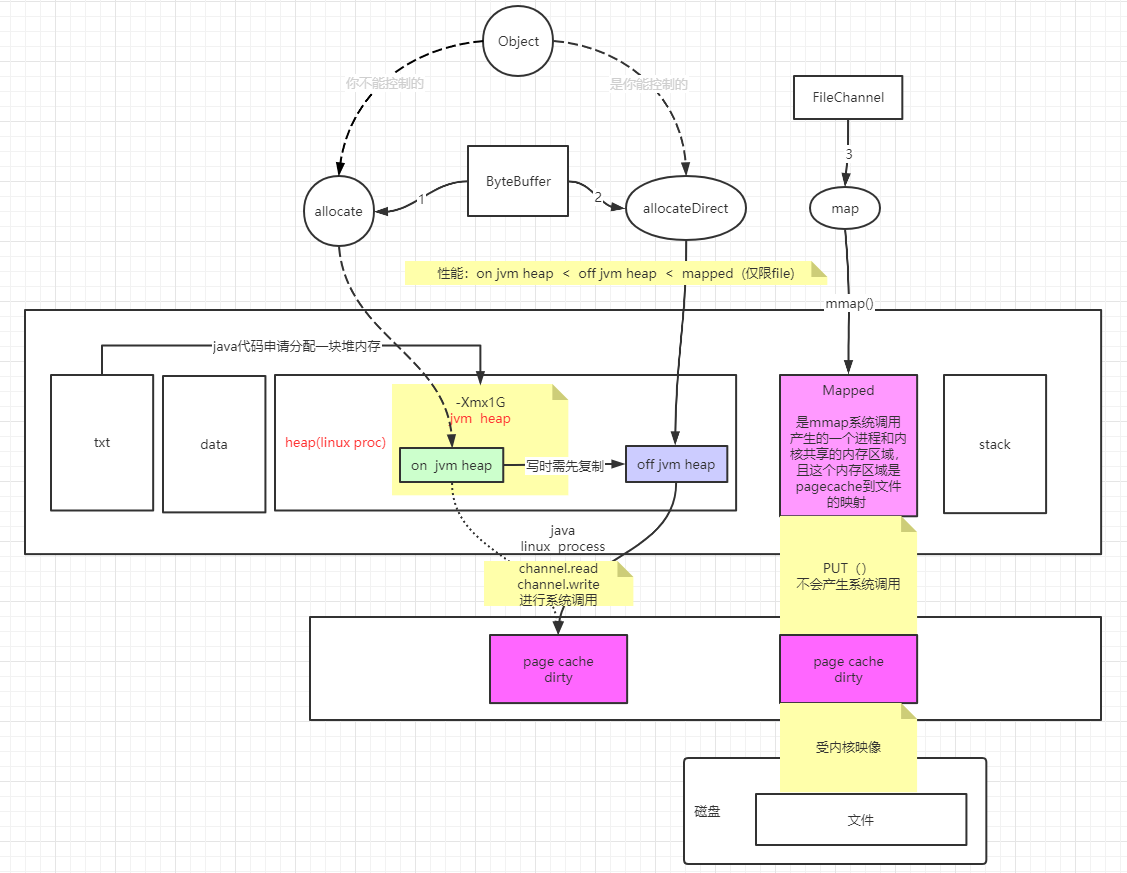
- txt为代码段、data为数据段
- 代码示例
io/nio示例
1 | import java.io.BufferedOutputStream; |
网络IO
- 一#177
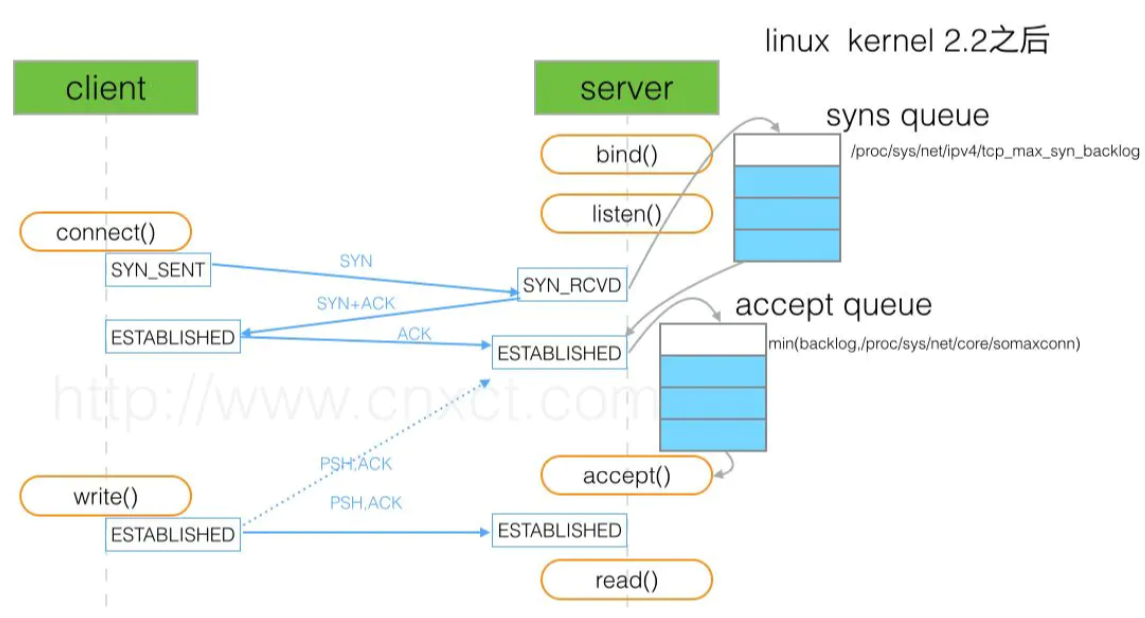
TCP握手时服务器资源开辟流程
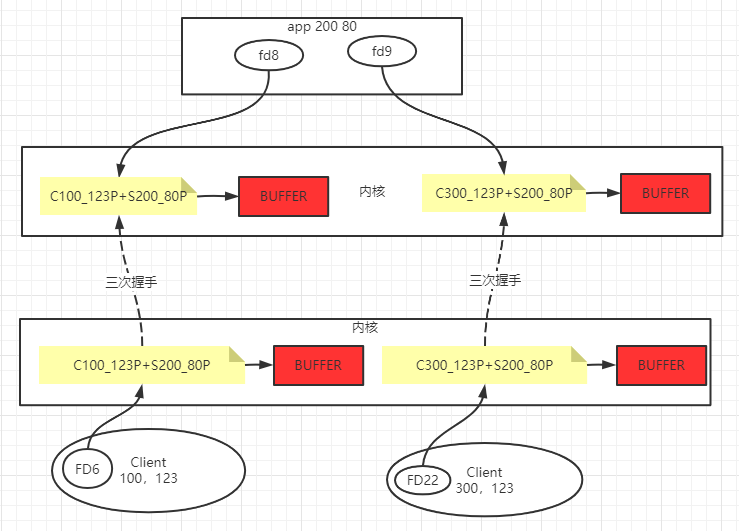
TCP相关参数,详细参考cn.aezo.netty.c3_io_tcp.T1_Server_Properties&T1_Client
backlog参数示意图
- tcp_max_syn_backlog是指定所能接受SYN同步包的最大客户端数量
- somaxconn是指服务端所能accept,即处理数据的最大客户端数量
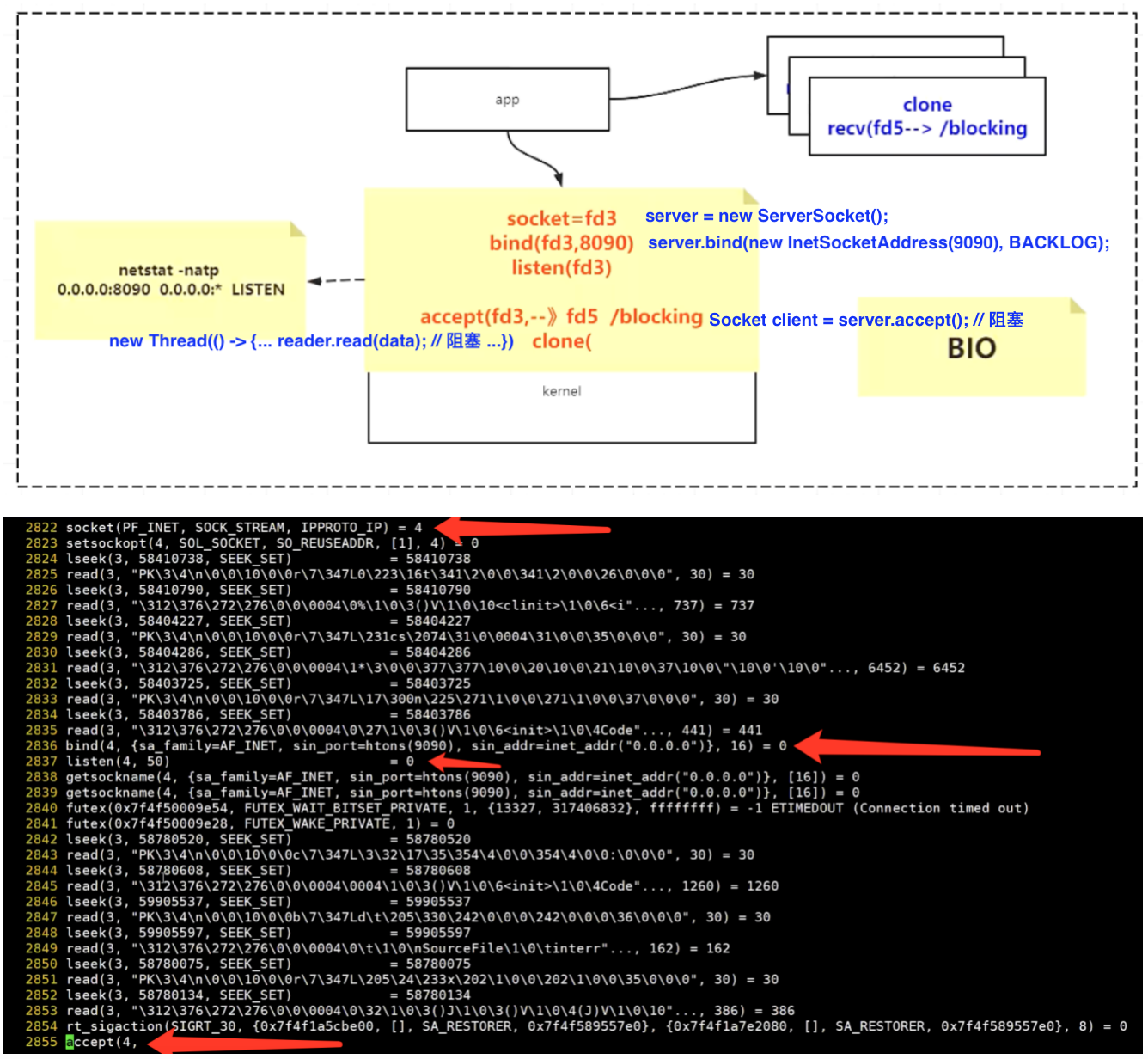
BIO服务器创建资源过程(系统调用语句)
C10K问题,即单机1万个并发连接问题 (一#184)
- BIO缺点
- 阻塞的,从而每个客户端需要创建一个线程进行read
- 并且每次循环read,会产生无意义的系统调用(NIO也存在此缺点)
- NIO解决的问题和缺点
- NIO相比BIO优势:非阻塞时,可通过1个或几个线程,来解决N个IO连接的处理
- 仍存在的缺点:每循环一次,read为O(n)复杂度,很多read调用是无意义的(客户端并没有发数据过来),但是每次会产生系统调用
- 多路复用器(如netty中的),参考下文
- 多路指多个IO,复用指进行一次系统调用,便可知道那些IO(文件描述符)是有数据的;然后用户程序对有数据的IO进行read调用
- 多路服务器包含select/poll/epoll等,详见下文
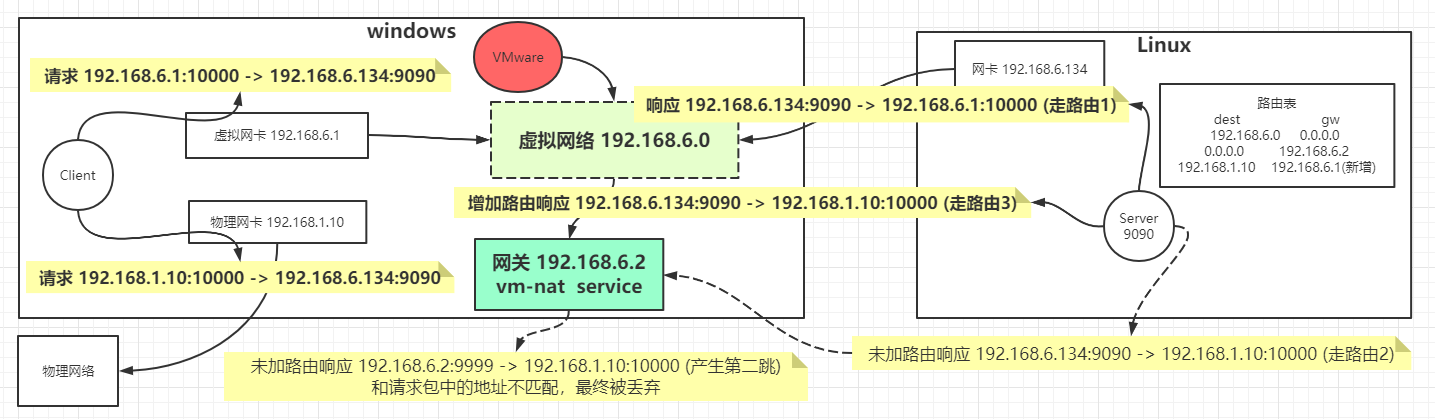
C10K测试客户端,测试过程中关于路由问题如下图
- BIO缺点
- BIO/NIO下建立TCP连接时系统调用情况(通过strace监测),详细参考cn.aezo.netty.c5_io_bio_nio.T1_Server_BIO&T2_Server_NIO
多路复用器(一#185)
- 测试案例SocketMultiplexingSingleThreadV1.java
- select/poll/epoll/kqueue => netty
select:synchronous I/O multiplexing,遵循POSIX规范的多路复用器,限制是一次调用只能检查FD_SETSIZ(1024)个文件描述符。man-pages(man select)中方法描述为int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);timeout可已设置超时时间poll:wait for some event on a file descriptor,类似select,无FD_SETSIZ限制。方法为int poll(struct pollfd *fds, nfds_t nfds, int timeout);epoll:I/O event notification facility,基于事件通知,包含epoll_create、epoll_ctr、epoll_wait。效率高于select/pollkqueue:类似epoll,只不过是unix系统上的
多路复用器示意图
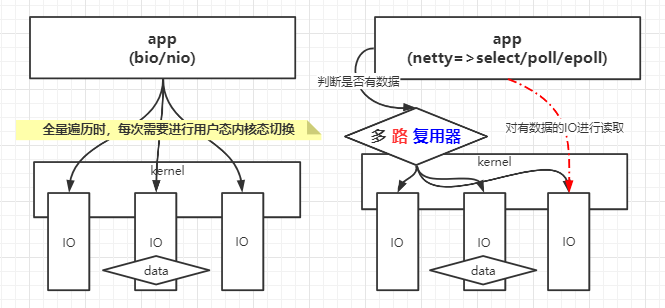
select/poll/epoll对比图
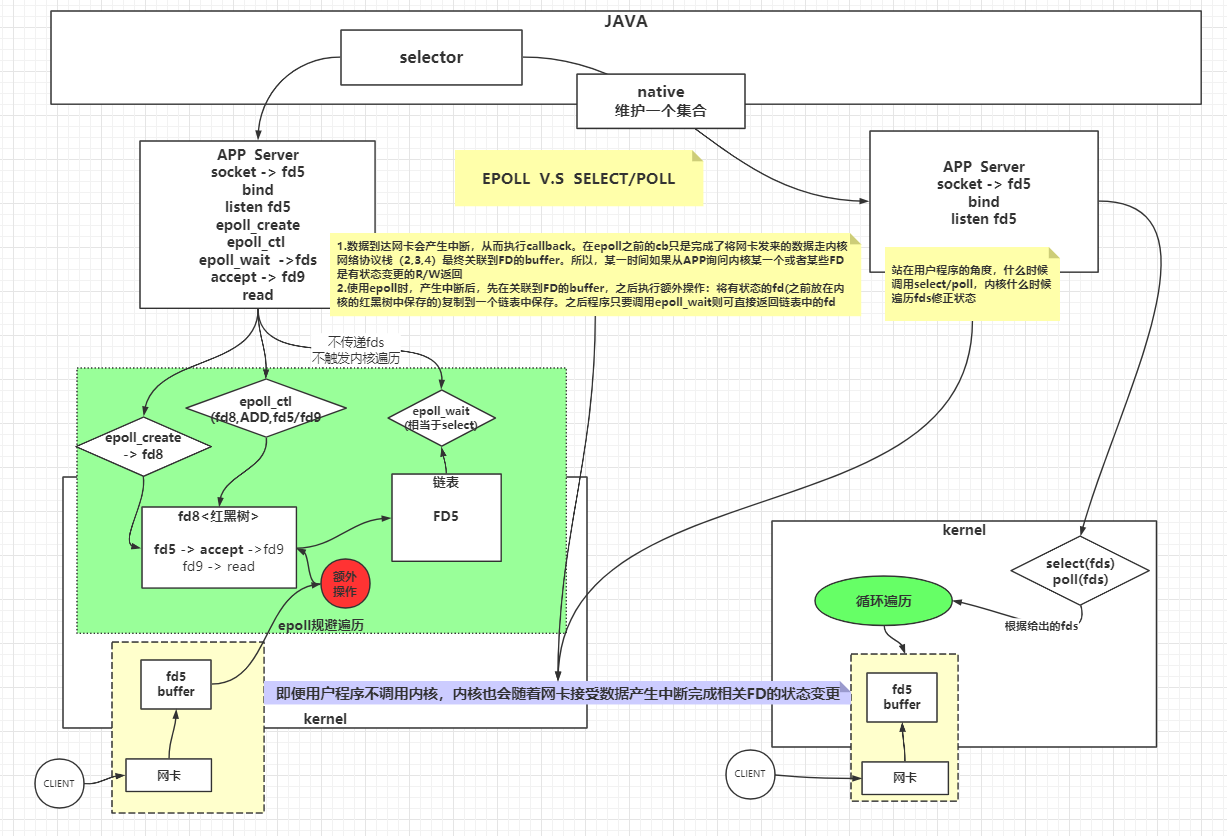
- 复杂度
- 单路IO(BIO/NIO),每次循环需要对有IO进行系统调用,复杂度为O(n)
- 多路复用器select/poll,每次select(fds)获取有状态的FD时,只需进行一次系统调用,复杂度为O(1);但是对有状态的IO遍历read时,时间复杂度为O(m)
- 无论NIO/SELECT/POLL都是要遍历所有的IO,询问状态
- 只不过NIO,这个遍历的过程成本在用户态内核态切换;多路复用器select/poll,这个遍历的过程触发了一次系统调用,用户态内核态的切换,每次会把fds传递给内核,内核重新根据用户这次调用传过来的fds,遍历修改状态
- select/poll的弊端
- 每次都要重新传递fds(内核开辟空间)
- 每次,内核被调了之后,针对这次调用,触发一个遍历fds全量的复杂度
- 多路复用器epoll,每次epoll_wait获取有状态IO时(类似select,只不过select是需要遍历),是从链表中获取数据,复杂度为O(1)
汇编实现引导程序
- 编写汇编码
1 | ; 文件名 boot.asm |
- 编译和制作启动软盘
1 | # 在centos上运行即可 |
- 用软盘启动系统
- 将上述制作的软盘 myos.img 下载到 windows
- VMWare 创建空的虚拟机
- 文件 - 创建新的虚拟机 - 典型 - 稍后安装操作系统 - 其他(版本其他) - 一路 next 完成
- 虚拟机设置:去掉 CD/DVD 选项中”启动时连接” - 网络,选择”仅主机模式”,勾选”启动时连接” - 添加软盘驱动器,使用软盘映像,找到 myos.img
- 启动虚拟机
- 显示 hello world, welcome to OS!
- 为什么主引导记录的内存地址是 0x7C00?
参考文章
