简介
- Ceph官网、官方文档 v14.2.4 Nautilus、官方中文文档、github源码
- Ceph 提供3种存储类型 ^1
- 块存储(
RBD)- 典型设备: 磁盘阵列,硬盘。主要是将裸磁盘空间映射给主机使用的
- 优点:多块廉价的硬盘组合起来提高容量;缺点:主机之间无法共享数据
- 使用场景:docker容器、日志、文件
- RBD是Ceph面向块存储的接口。这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block Driver 接口
- 相关块存储:Ceph 的 RBD、AWS 的 EBS、阿里云的盘古系统。在常见的存储中 DAS、SAN 提供的也是块存储
GlusterFS只提供对象存储和文件系统存储,而Ceph则提供对象存储、块存储以及文件系统存储
- 文件存储
- 典型设备:FTP、NFS服务器。为了克服块存储文件无法共享的问题,所以有了文件存储
- 优点:方便文件共享;缺点:读写速率低
- 使用场景:日志、有目录结构的文件存储
- 通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式存储提供了并行化的能力。如 Ceph 的 CephFS(CephFS是Ceph面向文件存储的接口),但是有时候又会把 GlusterFS、HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是属于文件系统存储
- 对象存储
- 典型设备:内置大容量硬盘的分布式服务器(Swift 、S3 以及 Gluster)
- 优点:具备块存储的读写高速,具备文件存储的共享等特性
- 使用场景:适合更新变动较少的数据,如:图片存储、视频存储
- 也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展
- 块存储(
Ceph 组件及概念 ^1
Ceph核心组件包括:Ceph OSDs、Monitors、Managers、MDSs。Ceph存储集群至少需要一个Ceph Monitor,Ceph Manager和Ceph OSD。使用Ceph Filesystem文件存储时也需要Ceph元数据服务器(Metadata Server);使用对象存储则另需要部署rgw(Gateway)
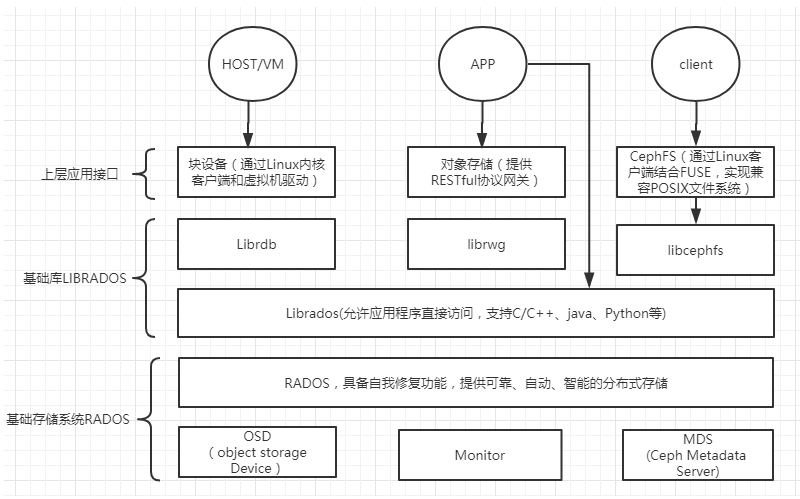
Monitor:负责监视整个集群的运行状况,信息由维护集群成员的守护程序来提供- Ceph Monitor(ceph-mon)维护着展示集群状态的各种图表,包括监视器图、OSD 图、归置组(PG)图、和 CRUSH 图。 Ceph 保存着发生在Monitors、OSD 和 PG上的每一次状态变更的历史信息(称为 epoch)。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常至少需要3个监视器
- 不存储任何数据,主要包含以下Map
Monitor map:包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过ceph mon dump查看 monitor mapOSD map:包括一些常用的信息,如集群ID、创建OSD map的 版本信息和最后修改信息,以及pool相关信息,主要包括pool 名字、pool的ID、类型,副本数目以及PGP等,还包括数量、状态、权重、最新的清洁间隔和OSD主机信息。通过命令ceph osd dump查看PG map:包括当前PG版本、时间戳、最新的OSD Map的版本信息、空间使用比例,以及接近占满比例信息,同时包括每个PG ID、对象数目、状态、OSD 的状态以及深度清理的详细信息。通过命令ceph pg dump可以查看相关状态CRUSH map: 包括集群存储设备信息,故障域层次结构和存储数据时定义失败域规则信息。相关命令ceph osd crush xxxMDS map:包括存储当前 MDS map 的版本信息、创建当前的Map的信息、修改时间、数据和元数据POOL ID、集群MDS数目和MDS状态,可通过ceph mds dump查看
OSDs(Object Storage Device/Daemon)- Ceph OSD 守护进程(ceph-osd)的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他 OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。冗余和高可用性通常至少需要3个Ceph OSD。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态(Ceph 默认有3个副本)
- 是由物理磁盘驱动器、在其之上的 Linux 文件系统以及 Ceph OSD 服务组成。Ceph OSD 将数据以对象的形式存储到集群中的每个节点的物理磁盘上,完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区
Managers: Ceph Manager守护进程(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。Ceph Manager守护进程还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的Ceph Manager Dashboard和 REST API。高可用性通常至少需要2个管理器MDS(Ceph Metadata Server):Ceph 元数据服务器(MDS)为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS)。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令RADOSGW(rgw):对象网关(Gateway)守护进程,提供对象存储服务。使用对象存储则另需要部署RADOS(Reliable Autonomic Distributed Object Store):RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致librados和 RADOS 交互的基本库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。Ceph 通过原生协议和 RADOS 交互,Ceph 把这种功能封装进了 librados 库,这样也能定制自己的客户端ADOS块设备:能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上CephFS:Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口Pool是存储空间的逻辑划分,一个集群可以分成多个Pool。Pool与数据安全策略相联系,定义池就要同时定义出Pool的pg数量和数据冗余策略(副本数和纠删码,以及使用的crush规则)PG(Placement Grouops):是ceph的逻辑存储单元
手动安装(基于ceph-deploy安装)
- 准备工作(所有节点运行)
1 | # node1(192.168.6.131) mon osd mgr deploy(部署节点) |
- 安装ceph-deploy(deploy节点运行)
1 | # 添加 Ceph 源。baseurl中的`rpm-nautilus`可换成`rpm-其他ceph版本` |
- 安装Storage Cluster(deploy节点运行)
1 | # 参考:https://docs.ceph.com/docs/nautilus/start/quick-ceph-deploy/#create-a-cluster |
- (可选)启用Dashboard(mgr节点运行)
1 | yum install ceph-mgr-dashboard |
- 安装失败可进行清理环境后重新安装
1 | ceph-deploy purge node1 node2 node3 # 如果执行purge,则需要重新对该节点安装ceph |
简单使用
块设备使用(rbd)
ceph集群外机器(客户端)使用ceph的rbd存储
yum install -y ceph-common安装rbd操作工具(参考上文增加rpm源配置)- 将ceph服务器的
/etc/ceph/目录下的集群配置文件ceph.conf和客户端秘钥文件ceph.client.admin.keyring复制到客户端机器的/etc/ceph目录
以集群内机器为例
1 | # 块设备使用。参考:https://docs.ceph.com/docs/nautilus/start/quick-rbd/#create-a-block-device-pool |
文件存储使用(CephFS)
- 文件存储使用的是OSD剩余空间,和rbd没有关系
- 测试过程
1 | # 文件存储使用(CephFS)。参考:https://docs.ceph.com/docs/nautilus/start/quick-cephfs/#create-a-filesystem |
- 创建不同用户和子目录来使用CephFS(上文
192.168.6.131:6789:/使用的是根目录) ^5
1 | ## mgr节点运行 |
- 常见错误
- 执行
ceph-fuse时提示failed to fetch mon config (--no-mon-config to skip)- 可能由于–keyring秘钥错误
- 执行
ceph-fuse时提示ceph-fuse[12595]: ceph mount failed with (2) No such file or directory- 本案例是因为
/aezo目录没有创建。可在上文myfs绑定的客户端目录(/mnt/mycephfs)下创建aezo目录 - 貌似还可以使用
cephfs-shell创建目录。关于cephfs-shell(目前处于alpha阶段)安装和使用可参考 https://docs.ceph.com/docs/master/cephfs/cephfs-shell/ 。其中cephfs-shell源码位于 https://raw.githubusercontent.com/ceph/ceph/v14.2.4/src/tools/cephfs/cephfs-shell
- 本案例是因为
- 执行
- 也可将CephFS导出为NFS服务器、在Hadoop中使用
对象存储
1 | # 对象存储使用。参考:https://docs.ceph.com/docs/nautilus/start/quick-rgw/ |
k8s使用ceph存储
直接使用
1 | ## 在Kubernetes(v1.15)集群的所有Node上安装Ceph-common包 |
- yaml文件
1 | ## ceph-secret.yaml |
使用rbd-provisioner(推荐)
rbd-provisioner为kubernetes 1.5+版本提供了类似于kubernetes.io/rbd的ceph rbd持久化存储动态配置实现 ^2- 如果使用kubeadm来部署集群,或者将
kube-controller-manager以容器的方式运行。这种方式下,kubernetes在创建使用ceph rbd pv/pvc时没任何问题,但使用dynamic provisioning自动管理存储生命周期时会报错,提示”rbd: create volume failed, err: failed to create rbd image: executable file not found in $PATH:”。问题来自gcr.io提供的kube-controller-manager容器镜像未打包ceph-common组件,缺少了rbd命令,因此无法通过rbd命令为pod创建rbd image - 安装及使用
1 | cd /root/k8s/ceph/rbd-provisioner |
- ceph-rbd-pool-default.yaml
1 | ## ceph-rbd-pvc-test.yaml (可选,测试自动创建PVC配置) |
运维案例
增加Ceph Node/添加OSD
1 | ## 增加Ceph Node相关操作(略):yum 源,免秘钥配置,ceph的版本,主机名,防火墙,selinux,ntp |
更换Ceph Node(更换osd、更换mon)
- 说明 ^3
- 原先有3个ceph节点(1个ssd+2个hhd),现需要将其中2个hhd节点(node2、node3)换成新的2个ssd节点(node4、node5)。且总共3个OSD,pool副本数设置为3
- 整个迁移过程将会消耗很长时间,此处由于涉及的osd较少,大概几个小时即可。如果数据较多,有可能迁移几天
- 实际测试过程中ceph状态为HEALTH_WARN(此时128个PG并非全部处于active状态)时,客户端无法使用存储;当ceph状态变为HEALTH_OK(128个PG都有active状态。如:1 active+recovering+remapped, 110 active+clean, 17 active+remapped+backfill_wait)时,客户端可正常使用
- 更换osd
1 | ## 以node4为例,node5同理 |
- 更换mon等
1 | ## 更新所有ceph节点的ceph.conf配置文件 |
删除OSD
1 | ## 将osd移出集群(此时osd状态由in up变为out up) |
镜像扩容缩容(rbd-images)
1 | ## 管理界面操作 |
常见问题
- 调试说明
- 日志目录
/var/log/ceph
- 日志目录
- 安装deploy时,提示
No module named pkg_resources- 解决:在deploy节点安装
wget https://bootstrap.pypa.io/ez_setup.py -O - | python(osd等节点可视情况安装)
- 解决:在deploy节点安装
- rbd map映射镜像时,提示
rbd: image ceph-image: image uses unsupported features: 0x38- 原因:CentOS的3.10内核仅支持layering、exclusive-lock,其他feature概不支持
- 解决
- 升级内核
- 或者手动disable镜像feature
rbd feature disable ceph-image object-map fast-diff deep-flatten exclusive-lock - 或者在各osd节点修改配置文件
/etc/ceph/ceph.conf,添加配置rbd_default_features = 1。在创建镜像时指定–image-format参数如:rbd create ceph-image --size 10G --image-format 1 --image-feature layering
- 创建存储池时提示
pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)- 原因:测试环境只有3个osd,设置复制个数为3,且每个osd默认最大pg数为250(mon_max_pg_per_osd)。而且已经创建过一个pood(128个pg),因此创建第二个pool(128个pg)则报错,超过osd最大pg限制
- 解决:增加osd数,或临时提高osd最大pg数(正式环境不建议太高),或者将pool的pg设置的小一些。参考PG
k8s pod创建时提示
MountVolume.WaitForAttach failed for volume "ceph-pv" : rbd image rbd/ceph-image is still being used- 原因:强制删除了pod,导致重新创建此pod时,改镜像被旧pod锁定
解决
1
2
3
4# 查看锁定
rbd lock ls ceph-image
# 解除锁定
rbd lock rm rbd/ceph-image "auto 18446462598732840961" client.4259
k8s pod创建时提示
MountVolume.WaitForAttach failed for volume "ceph-pv" : rbd: map failed exit status 110...unable to find a keyring on /etc/ceph/ceph.client.admin.keyring...Connection timed out,调度到对应的k8s节点上提示missing required protocol features(dmesg -T | grep ceph)- 原因:由于内核版本不够高导致一些 Ceph 需要的特性没有得到支持(此问题出现的版本为
Centos7 Linux 4.4.196-1) ^6 解决
1
2
3
4# mgr节点运行。修改 CRUSH MAP 的配置,将 chooseleaf_vary_r 与 chooseleaf_stable 设为 0
ceph osd getcrushmap -o crush # 产生crush临时文件
crushtool -i crush --set-chooseleaf_vary_r 0 --set-chooseleaf_stable 0 -o crush.new # 产生crush.new临时文件
ceph osd setcrushmap -i crush.new
- 原因:由于内核版本不够高导致一些 Ceph 需要的特性没有得到支持(此问题出现的版本为
ceph警告
HEALTH_WARN application not enabled on 1 pool(s),且通过k8s storageClass创建的镜像无法查询到- 原因:新创建的pool没有开启rbd application
- 解决:
ceph osd pool application enable kube rbd(此处存储池为kube)
rbd: error: image still has watchers无法删除镜像,参考:https://www.cnblogs.com/sisimi/p/7776633.html- 原因:镜像无法删除的原因一般为存在快照或者watcher(此情况)
解决
1
2
3
4
5
6## 存在watcher的情况
rbd status kube/img # 获取kube/img镜像的watcher
ceph osd blacklist add 192.168.6.131:0/1135656048 # 添加watcher到黑名单1h(1小时候会自动移除)
# rbd rm kube/img # 可选,删除镜像
# ceph osd blacklist rm 192.168.6.131:0/1135656048 # 手动移除黑名单
ceph osd blacklist ls # 查看黑名单
更换mon时,执行
ceph-deploy mon add node4报错admin_socket: exception getting command descriptions: [Errno 2] No such file or directory- 解决:修改
ceph.conf文件中的mon_host、public_network并推送到所有节点 ^7
- 解决:修改
相关命令
常用
1 | ceph -s/-w # 查看集群状态(-w实时状态查看) |
ceph
- 概要
1 | ceph -h # 查看帮助(非常多命令)。查看某个命令帮助:`ceph -h osd pool` |
ceph config
1 | ### ceph config <xxx>. eg: `ceph config ls` |
ceph osd
ceph osd pool
1 | ### ceph osd pool <xxx>。eg: `ceph osd pool ls` |
ceph osd crush
1 | ## ceph osd crush -h |
ceph osd
1 | ### ceph osd <xxx> |
ceph xxx
1 | ### ceph tell |
Local commands
- Local commands表示只能在角色所在的主机上进行设置,其他一般为Monitor commands(在mon节点上设置即可)
1 | ceph daemon {type.id|path} <cmd> # 基于某个角色的守护进程执行相关命令 |
ceph-volume
- 作用:使用物理磁盘或lvm创建Ceph OSDs(各Storage Node均可运行)
- Doc
- https://www.dovefi.com/post/ceph-volume%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90osd%E5%88%9B%E5%BB%BA%E5%92%8C%E5%BC%80%E6%9C%BA%E8%87%AA%E5%90%AF/
1 | ceph-volume -h |
rbd 块存储
ceph-common包中含有此命令
1 | See 'rbd help <command>' for help on a specific command. |
rados
ceph-common包中含有此命令
1 | rados -h |
ceph.conf 配置文件
ceph-deploy new初始化出来的文件
1 | [global] |
- 字段说明
1 | ## monitors:https://docs.ceph.com/docs/nautilus/rados/configuration/common/#monitors |
进阶知识
PG和PGP
PG(Placement Groups) 它是ceph的逻辑存储单元。在数据存储到ceph时,先打散成一系列对象,再结合基于对象名的哈希操作、复制级别、PG数量,产生目标PG号。根据复制级别的不同,每个PG在不同的OSD上进行复制和分发。可以把PG想象成存储了多个对象的逻辑容器,这个容器映射到多个具体的OSD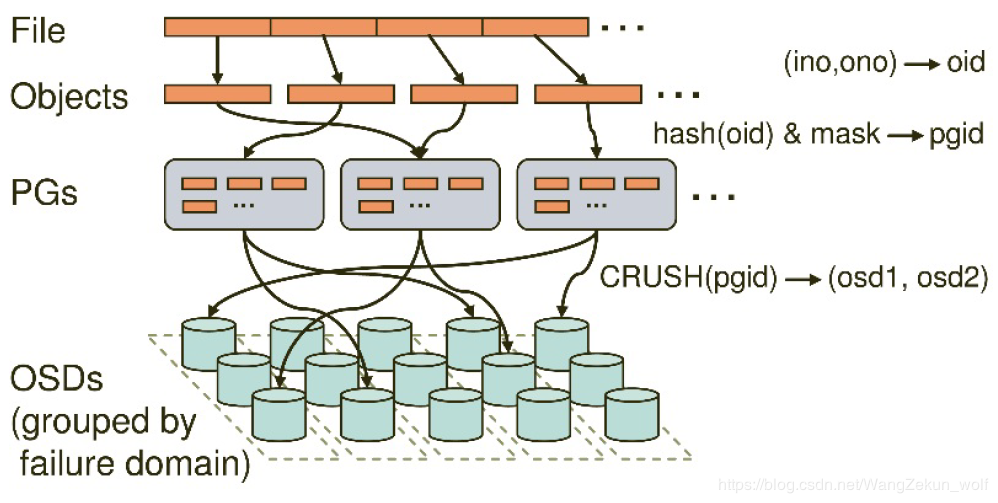
- PG存在的意义是提高ceph存储系统的性能和扩展性。如果没有PG,就难以管理和跟踪数以亿计的对象,它们分布在数百个OSD上。对ceph来说,管理PG比直接管理每个对象要简单得多
- 每个PG需要消耗一定的系统资源包括CPU、内存等。通常来说,增加PG的数量可以减少OSD的负载,一个推荐配置是每OSD对应50-100个PG。如果数据规模增大,在集群扩容的同时PG数量也需要调整。CRUSH会管理PG的重新分配
- Pool由PG构成,对象存到Pool是存到特定的PG中,可以理解为对象的虚拟目录。在创建Pool的时候就要把pg数量规划好,PG数量只可以增大不可以缩小
- 在架构层次上,PG 位于 RADOS 层的中间。往上负责接收和处理来自客户端的请求,往下负责将这些数据请求翻译为能够被本地对象存储所能理解的事务
- 正常的 PG 状态是
100% active + clean,这表示所有的 PG 是可访问的,所有副本都对全部 PG 都可用。PG 状态详解
PGP(Placement Group for Placement)对应Pool的PG和PGP个数调整
- PG是指定存储池存储对象的目录有多少个,PGP是存储池PG的OSD分布组合个数
- PG的增加会引起PG内的数据进行分裂,分裂到相同的OSD上新生成的PG当中
- PGP的增加会引起部分PG的分布进行变化,但是不会引起PG内对象的变动
相关命令
1
2
3
4
5
6
7
8
9
10
11
12
13ceph osd pool get rbd pg_num # 获取rbd池的pg数
ceph osd pool get rbd pgp_num # 获取rbd池的pgp数
# 调整PG数量
# 调整pg时,原则上每次增加一倍
# 此命令本质是当前pg的分裂(1个pg分裂成2个)。mon会首先更新自身的osd map中的pg数量,然后将osd map同步给osd;osd根据新的pg数量进行计算,进行本地分裂;分裂过程就是创建新目录,然后数据移动过去
# 分裂期间CPU和IO会打满,负载非常高,影响时间看数据量而定(30s-10min)
ceph osd pool set <pool_name> pg_num <pg_num>
# 调整PGP数量
# pg数量大于pgp数量时,heath状态显示warning。需要扩充pgp数量
# 调整pgp数量会使pg在集群内重新分布
# 该操作会影响一半的数据进行迁移,对集群影响非常大
ceph osd pool set <pool_name> pgp_num <pg_num>
每个Pool分配PG建议个数计算公式
Total PGs = ((Total_number_of_OSD * 100) / max_replication_count) / pool_count(结果往上取靠近2的N次方的值)OSD最大PG数默认为
mon_max_pg_per_osd=2501
ceph config get osd.0 mon_max_pg_per_osd # 获取osd.0的最大pg数
PG迁移
- 由于CRUSH算法的伪随机性,对于一个PG来说,如果 OSD tree 结构不变的话,它所分布在的 OSD 集合总是固定的(同一棵tree下的OSD结构不变/不增减),即此PG不会进行迁移。反之 OSD tree 变化则会触发PG迁移
参考文章
