简介
- Prometheus(普罗米修斯)、Docs
- 是一套开源的系统监控报警框架。现在已加入 Cloud Native Computing Foundation(CNCF),成为受欢迎度仅次于 Kubernetes 的项目
- Prometheus可基于如node_exporter进行监控,并提供PromQL查询语句来展示监控状态,但是PromQL不支持API server,因此中间可使用插件k8s-prometheus-adpater来执行API server的命令,并转成PromQL语句执行
架构 ^1
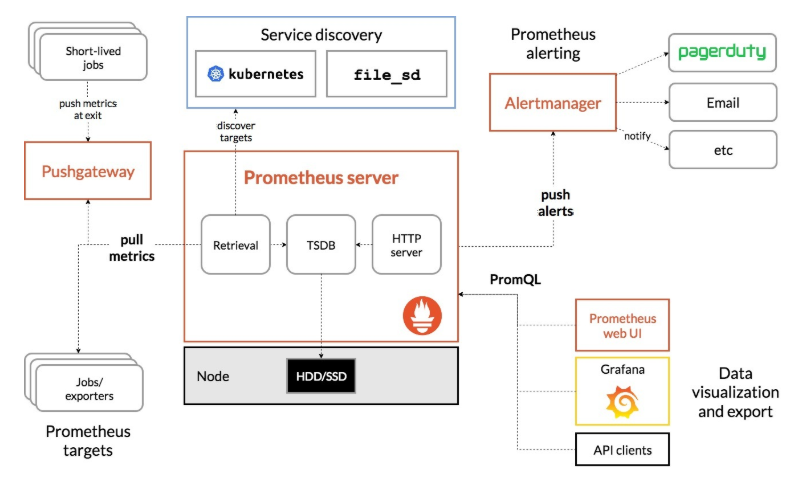
Prometheus Server主要用于抓取数据和存储时序数据,另外还提供查询和 Alert Rule 配置管理Client Libraries客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metricsPush Gateway推送网关,短期的监控数据的汇总节点。主要用于业务数据汇报等,此类数据存在时间可能不够长,Prometheus采集数据是用的pull也就是拉模型(如5秒钟拉取一次数据),导致此类数据无法抓取到,因此可以将他们推送到网关中,此时网关相当于一个缓存,之后仍然由Prometheus Server定期到Push Gateway上拉取数据Exporters进行各种数据汇报,例如汇报机器数据的node exporter,汇报 MongoDB 信息的MongoDB exporter等等Alertmanager从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。支持电子邮件、slack、pagerduty,hitchat,webhook、钉钉等
- Prometheus工作说明
- Prometheus需要的metrics,要么程序定义输出(模块或者自定义开发);要么用官方的各种exporter(node-exporter,mysqld-exporter,memcached_exporter…)采集要监控的信息,占用一个web端口然后输出成metrics格式的信息
- prometheus server去收集各个target的metrics存储起来(存储在TSDB时序数据库中)
- 用户可以在prometheus的http页面上用promQL(prometheus的查询语言)或者(grafana数据来源就是用)api去查询一些信息,也可以利用pushgateway去统一采集,然后prometheus从pushgateway采集(所以pushgateway类似于zabbix的proxy)
- 相关概念
- Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。metric 名字格式:
<metric name>{<label name>=<label value>, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}
- Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。metric 名字格式:
安装使用
基于docker安装
Prometheus Server 安装使用
- 安装命令 ^3
1 | cd /home/smalle/prom/prometheus |
- prometheus.yml(/home/smalle/prom/prometheus 目录)
1 | # 参考:https://prometheus.io/docs/prometheus/latest/configuration/configuration/ |
- rules.yml(/home/smalle/prom/prometheus 目录) 报警规则配置(需要配合Alertmanager使用,如使用Grafana告警则不需要)
1 | groups: |
Alertmanager 安装使用
- 安装(如使用Grafana告警则不需要安装,但是Grafana告警比较有限)
1 | cd /home/smalle/prom/alertmanager |
- alertmanager.yml
1 | # 参考 https://prometheus.io/docs/alerting/configuration |
Push Gateway 安装使用
- 安装及使用
1 | ## 安装 |
- server配置中需要添加pull拉取pushgateway节点任务
- 存在认证问题。直接推送到pushgateway路径
http://192.168.6.131:9091/metrics/job/<my_job>/instance/<my_instance>(my_instance如hostname或ip),然后server根据my_job和my_instance进行记录,server无需其他额外配置 适用于监控服务器(A)和被监控服务器(B)不在同一网络,且B无法开通额外的外网端口。此时可在B上启动Exporter,并通过定时curl将本地监控数据转交到A
1
2
3
4
5
6## B服务器
# crontab
*/1 * * * * /root/script/push-metrics.sh > /dev/null 2>&1 &
# push-metrics.sh
curl -s http://localhost:9100/metrics | curl --data-binary @- http://pushgateway.aezo.cn/metrics/job/my-app/instance/my-node
基于prometheus-operator安装prometheus(k8s环境)
- 基于Helm安装(推荐)
- prometheus-operator ^2
Prometheus-operator的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator这个controller有BRAC权限下去负责监听这些自定义资源的变化。相关CRD说明Prometheus:由 Operator 依据一个自定义资源kind: Prometheus类型中,所描述的内容而部署的 Prometheus Server 集群,可以将这个自定义资源看作是一种特别用来管理Prometheus Server的StatefulSets资源ServiceMonitor:一个Kubernetes自定义资源(和kind: Prometheus一样是CRD),该资源描述了Prometheus Server的Target列表,Operator 会监听这个资源的变化来动态的更新Prometheus Server的Scrape targets并让prometheus server去reload配置(prometheus有对应reload的http接口/-/reload)。而该资源主要通过Selector来依据 Labels 选取对应的Service的endpoints,并让 Prometheus Server 通过 Service 进行拉取(拉)指标资料(也就是metrics信息),metrics信息要在http的url输出符合metrics格式的信息,ServiceMonitor也可以定义目标的metrics的urlAlertmanager:Prometheus Operator 不只是提供 Prometheus Server 管理与部署,也包含了 AlertManager,并且一样通过一个 kind: Alertmanager 自定义资源来描述信息,再由 Operator 依据描述内容部署 Alertmanager 集群PrometheusRule:对于Prometheus而言,在原生的管理方式上,我们需要手动创建Prometheus的告警文件,并且通过在Prometheus配置中声明式的加载。而在Prometheus Operator模式中,告警规则也编程一个通过Kubernetes API 声明式创建的一个资源.告警规则创建成功后,通过在Prometheus中使用想servicemonitor那样用ruleSelector通过label匹配选择需要关联的PrometheusRule即可- 注:安装下文安装完成后可通过
kubectl get APIService | grep monitor看到新增了v1.monitoring.coreos.com的APIService,通过kubectl get crd查看相应的CRD
- 基于prometheus-operator安装Prometheus
1 | # 下载 https://github.com/coreos/kube-prometheus/releases/tag/v0.1.0 中的 manifests 目录下所有文件 |
- 基于下列Ingress配置暴露服务到Ingress Controller。访问
http://grafana.aezocn.local/,默认用户密码admin/admin即可进入Grafana界面 - 可从Grafana模板中心下载模板对应的json文件,并导入到Grafana的模板中
1 | # prometheus-ingress.yaml |
Grafana
- Prometheus数据源说明:https://grafana.com/docs/features/datasources/prometheus/
label_values等函数,可在Variables > Edit -> Query Options -> Query属于表达式,在Preview of values中会显示表达式结果
- Dashboard
Grafana安装
1 | mkdir -p /home/smalle/prom/grafana |
基本使用
- 选择数据源:Configuration - Data Sources - Add data sources - Time series databases选择Prometheus
- 配置数据源:Data Sources/Prometheus/Settings - HTTP输入 http://192.168.6.131:9090 (Prometheus Server地址,或者如http://prometheus-server.monitoring.svc.cluster.local) - Save & Test
- 选择图表:Data Sources/Prometheus/Dashboards - Import一个图表(如Prometheus 2.0 Stats) - 选择Prometheus Stats - 即可看到图表展示
- 可从Grafana模板中心下载模板对应的json文件,并导入到Grafana的模板中
- Prometheus数据源推荐模板
- Kubernetes相关:
8588(可选择deploy/node进行统计CPU和内存)、7249(汇总所有的节点统计CPU和内存) - Node Exporter相关:
8919、1860(选择某一个节点,分类展示系统信息) - Blackbox Exporter:9965
- Kubernetes相关:
- Prometheus数据源推荐模板
- 插件安装
- 安装后需要重启grafana服务,k8s-helm安装的pod重新创建后插件和Dashboard还在(已经持久化到磁盘)
grafana-cli plugins install grafana-piechart-panel安装Pie Chart插件
自定义图表
- Create - Dashboard - New Panel(新建一个图表) - Add Query
- Query查询配置:选择数据源Prometheus
- 选择Metrics指标(所有metrics根据命名的第一个_进行分类)
- Legend为指标说明(标题)
- 可Add Query继续增加指标
- Visualization可视化配置
- General基本配置
- Title设置图标标题
- Alerting告警配置
- 如果某图表使用模板变量,则该图表不能配置告警(单独配置个告警的视图,用正则匹配出所有的主机或者每台主机单独一个查询语句);告警只支持graph的图表
- 右上角保存Save Dashboard
告警插件(默认安装)
- Grafana是基于图表进行告警,Alertmanager则没有此限制,可同时使用
- Alerting/Alert Rules 查看告警规则,新增需要在每个Panel的设置中进行
- Notification channels 设置告警通道,可使用Email(可以定义多个邮件通道)、webhook、Slack、钉钉(DingDing)等
- 使用邮件通道时,需提前配置邮件发送服务器
- Slack配置(参考上文Alertmanager)
- Url填写slack应用对应地址
- Recipient为slack通道,如
#monitor
Exporter
- 官方推荐的Exporter
- 与Prometheus服务端安装无关,一般由被监控的客户端安装。此处仅为了演示exporter如何输出metrics格式的信息,并由Prometheus Server采集
- 需要Server到Exporter节点Pull(因此Exporter节点对应端口需对外开放)
- 采集参考采集文本说明,客户端(Exporter)需要按照一定的格式上报metric
node_exporter (官方)
- node_exporter 主要采集节点系统性能指标(cpu/mem/disk)并提供查询
手动安装(配合自动重启)
- 快速安装
bash <(curl -L https://raw.githubusercontent.com/oldinaction/scripts/master/shell/prod/install-prometheus-node_export.sh) 2>&1 | tee my.log 安装步骤
1
2
3
4
5
6
7wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
tar -xvzf node_exporter-0.18.1.linux-amd64.tar.gz # 只有一个node_exporter的可执行程序
mv node_exporter-0.18.1.linux-amd64/node_exporter /usr/sbin/node_exporter # 可删除下载文件
# 启动服务,默认监听9100端口,正式环境可自定义成服务后台运行(如果要暴露外网,可修改此端口)。`./node_exporter -h` 查看参数设置
/usr/sbin/node_exporter
# 查看metrics信息
curl http://localhost:9100/metrics- 在prometheus中添加此Exporter的爬取配置
- 快速安装
- 如果Node Exporter处于防火墙中,则server无法爬取。此时只能push推送到PushGateway,临时解决方案如
- 通过 cronjob 每分钟(类似server拉取频率)执行脚本
curl -s http://localhost:9100/metrics | curl --data-binary @- http://pushgateway.example.org/metrics/job/some_job/instance/some_instance^5
- 通过 cronjob 每分钟(类似server拉取频率)执行脚本
- 基于docker安装
1 | docker run -d --name=node-exporter -p 9100:9100 prom/node-exporter |
blackbox_exporter 网络探测-黑盒监控(官方)
- blackbox_exporter 可以提供
http、tcp、icmp、dns的监控数据采集。应用场景- HTTP 测试
- 定义 Request Header 信息
- 判断 Http status / Http Respones Header / Http Body 内容
- TCP 测试
- 业务组件端口状态监听
- 应用层协议定义与监听
- ICMP 测试
- 主机探活机制
- POST 测试
- 接口联通性
- SSL 证书过期时间
- HTTP 测试
- 安装(只需服务端安装,客户端无需安装)
1 | ## 安装 |
- 在prometheus中添加此Exporter的爬取配置
1 | ## HTTP 监控 |
- 结合k8s时,prometheus配置示例(基于helm部署,参考http://blog.aezo.cn/2019/09/19/devops/prometheus/)
1 | extraScrapeConfigs: | |
采集和PromQL查询
样本、指标 ^4
- Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。time-series是按照时间戳和值的序列顺序存放的,称之为向量(vector)。每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名
- 在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成
- 指标(metric):metric name和描述当前样本特征的labelsets
- 时间戳(timestamp):一个精确到毫秒的时间戳
- 样本值(value): 一个float64的浮点型数据表示当前样本的值
- 指标(Metric)格式如
metric_name [ {label_name1="label_value1",label_name2=label_value2} ] value [ timestamp ]api_http_requests_total{method="POST", handler="/messages"}等同于{__name__="api_http_requests_total", method="POST", handler="/messages"}
采集文本说明
- 客户端(Exporter)需要按照一定的格式上报metric
- Exporter 收集的数据转化的文本内容以行
\n为单位,空行将被忽略- 如果以
#开头通常表示注释,不以#开头,表示采样数据 - 以
# HELP开头表示 metric 帮助说明 - 以
# TYPE开头表示定义 metric 类型,包含counter,gauge,histogram,summary, 和untyped(默认) 类型 - 其他
#开头认为是普通注释
- 如果以
- 采样数据格式
metric_name [ {label_name1="label_value1",label_name2=label_value2} ] value [ timestamp ]- 其中metric_name和label_name必须遵循PromQL的格式规范要求。value是一个float格式的数据,timestamp的类型为int64(从1970-01-01 00:00:00以来的毫秒数),timestamp为可选默认为当前时间。具有相同metric_name的样本必须按照一个组的形式排列,并且每一行必须是唯一的指标名称和标签键值对组合
- 假设采样数据 metric 叫做
x,且x是 histogram 或 summary 类型必需满足以下条件- 采样数据的总和应表示为
x_sum;总量应表示为x_count - summary 类型的采样数据的 quantile 应表示为
x{quantile="y"} - histogram 类型的采样分区统计数据将表示为
x_bucket{le="y"};必须包含x_bucket{le="+Inf"}, 它的值等于x_count的值 - summary 和 historam 中 quantile 和 le 必需按从小到大顺序排列
- 采样数据的总和应表示为
PromQL查询
PromQL语法示例
1 | ## 查询时间序列。瞬时向量表达式(查询的最新数据) |
常用查询
1 | # exporter的可用性监控 |
参考文章
