简介
- Helm 、Helm Docs、Helm 指南(中文)
- 是 Kubernetes 上的包管理器
- Helm组成:
Helm客户端、Tiller服务器、Charts仓库 - 原理:Helm客户端从远程Charts仓库(Repository)拉取Chart(应用程序配置模板),并添加Chart安装运行时所需要的Config(配置信息),然后将此Chart和Config提交到Tiller服务器,Tiller服务器则在k8s生成
Release,并完成部署
- 官方Charts仓库、官方Charts仓库展示、Kubeapps Charts仓库(速度较快)
- 国内docker镜像
安装Helm客户端及服务
安装Helm客户端
1
2
3
4
5
6
7# 下载helm命令行工具到master节点
curl -O https://get.helm.sh/helm-v2.14.2-linux-amd64.tar.gz
tar -zxvf helm-v2.14.2-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/
# 查看帮助
helm
rm -rf linux-amd64 # 删除下载文件安装Tiller服务器(安装在k8s集群中) ^1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 为了安装服务端tiller,还需要在这台机器上配置好kubectl工具和kubeconfig文件,确保kubectl工具可以在这台机器上访问apiserver且正常使用。一般安装在master
# 因为Kubernetes APIServer开启了RBAC访问控制,所以需要创建tiller使用的`service account: tiller`,并分配合适的角色给它
kubectl create serviceaccount --namespace kube-system tiller
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
# 使用helm部署tiller。-i指定自己的镜像,因为官方的镜像因为某些原因无法拉取,官方镜像地址是:gcr.io/kubernetes-helm/tiller:v2.14.2
helm init --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.2 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 为应用程序设置serviceAccount
kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
# 检查是否安装成功
kubectl -n kube-system get pods|grep tiller
# Client 和 Server 都显示各自版本,即表示 Client 和 Server 均正常
helm version
# (可选)查看并修改远程仓库地址。上文默认使用了阿里的镜像
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo update
helm repo list
# 卸载tiller
heml reset
Helm命令 ^2
1 | # helm |
Helm传递参数
- 通过
--set直接传入参数值,如:helm install stable/mysql --set mysqlRootPassword=Hello1234! -n my-dev 生成自定义 values 文件
1
2
3
4
5
6
7# 生成 values 文件
helm inspect values stable/mysql > myvalues.yaml
# 修改参数值
vi myvalues.yaml
# 基于某个 values 文件进行安装,此文件和默认文件会进行值合并覆盖
helm install stable/mysql -f myvalues.yaml
helm install --values=myvalues.yaml stable/mysqlvalues.yaml和--set联合使用时,–set的优先级更高1
helm upgrade --install oa-dev-center --namespace devops -f oa-dev-center-api/devops/values.yaml --set 'image.repository=192.168.10.130/devops/oa-dev-center,image.tag=1.0.0-SNAPSHOT' aezo/springboot --version 1.0.0 --dry-run --debug
- 通过
Chart使用(手动创建)
- 安装某个 Chart 后,可在
~/.helm/cache/archive中找到 Chart 的 tar 包,可解压查看 Chart 文件信息(tar -zxvf nginx-ingress-0.9.5.tgz) 创建 Chart 案例 ^1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 创建名为 mychart 的 Chart. 此时会创建一个包含nginx相关配置的的模板包
helm create mychart
# tree mychart
# 检测 chart 的语法
helm lint mychart
# **模拟安装 chart**,并输出每个模板生成的 YAML 内容(--dry-run 实际没有部署到k8s)
helm install --dry-run --debug mychart
# 部署到k8s
helm install ./mychart --name mychart --namespace test
helm upgrade mychart ./mychart
# 测试
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=mychart,app.kubernetes.io/instance=test-chart" -o jsonpath="{.items[0].metadata.name}")
kubectl port-forward --address 0.0.0.0 $POD_NAME 8080:80
# 在本地访问http://127.0.0.1:8080即可访问到nginx
# 修改配置文件(也可同时配合--set修改配置)后更新部署
# 此处image.tag不能使用过长的数字(yyyyMMddHHmmss生成的数字),过长传递到k8s则变成了科学计数导致出错
helm upgrade --set image.tag=20190902 mychart ./mychart
helm history mychart # 查看更新历史
## 复制后修改项目名
sed -i 's/mychart/mychart2/g' `grep mychart -rl ./mychart2`tree mychart显示目录信息如下1
2
3
4
5
6
7
8
9
10
11
12
13
14# 其中 Chart.yaml 和 values.yaml 必须,其他可选
mychart
├── charts # 依赖的chart。如 https://hub.kubeapps.com/charts/bitnami/elasticsearch,elasticsearch依赖了kibana
├── requirements.yaml # 该chart的依赖配置(create创建的无此文件)
├── Chart.yaml # Chart本身的版本和配置信息。其中的name是chart的名称,并不一定是release的名称
├── templates # 配置模板目录,下是yaml文件的模板,遵循Go template语法
│ ├── deployment.yaml # kubernetes Deployment object
│ ├── _helpers.tpl # 定义了一些基础模板(一般是一些全局变量),如`{{- define "harbor.fullname" -}}`
│ ├── ingress.yaml # kubernetes Ingress(默认未启用)
│ ├── NOTES.txt
│ ├── service.yaml # kubernetes Serivce
│ └── tests
│ └── test-connection.yaml
└── values.yaml # kubernetes object configuration比如在
deployment.yaml中定义的容器镜像1
2
3# 其中`.Values`代表后面属性获取`values.yaml`文件中的数据,如`.Values.image.repository`就是`nginx`,`.Values.image.tag`就是`stable`
# Values为内置对象。更多内置对象参考:https://whmzsu.github.io/helm-doc-zh-cn/chart_template_guide/builtin_objects-zh_cn.html
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
打包分享
chart 通过测试后可以将其添加到仓库,团队其他成员就能够使用。任何 HTTP Server 都可以用作 chart 仓库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19## 在node2启动一个 HTTP Server,如果已有可忽略。此处node2服务地址为 http://192.168.6.132:8080/
docker run -d -p 8080:80 -v /var/www/:/usr/local/apache2/htdocs/ httpd
## 在node1操作
# 生成压缩包 mychart-0.1.0.tgz,并同步到 local 的仓库
helm package mychart
# 生成仓库的 index 文件
mkdir myrepo
mv mychart-0.1.0.tgz myrepo/
# Helm 会扫描 myrepo 目录中的所有 tgz 包并生成 index.yaml
helm repo index myrepo/ --url http://192.168.6.132:8080/charts
cat myrepo/index.yaml
# 需要提前在node2创建 /var/www/charts/
scp myrepo/* root@node2:/var/www/charts/
helm repo add newrepo http://192.168.6.132:8080/charts
helm repo list
helm search mychart
# 如果以后仓库添加了新的 chart,需要用 helm repo update 更新本地的 index
helm repo update
chart语法参考Go template语法
- chart参考文章chart_template_guide
- chart内置对象
Release.NameRelease.Namespace
- chart内置对象
使用案例
MySQL
1 | cat > mysql-values.yaml << 'EOF' |
- k8s集群内部连接的主机名为
mysql-devops.devops.svc.cluster.local
练手Helm
1 | ## 准备 |
- mysql-pv.yaml
1 | apiVersion: v1 |
cert-manager
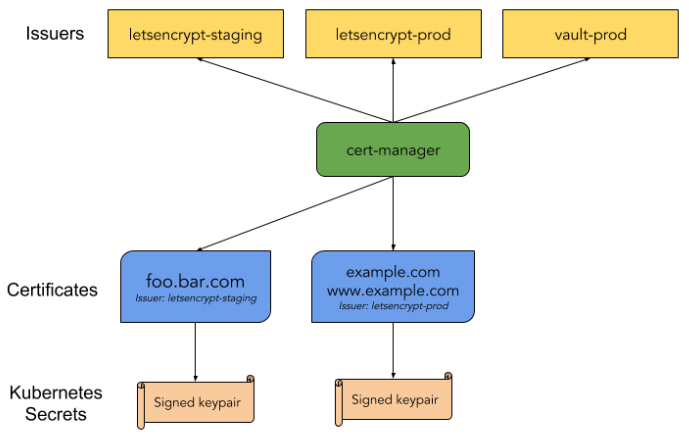
1 | ## 安装 |
- cert-manager-values.yaml
1 | image: |
- cluster-issuer.yaml
1 | apiVersion: cert-manager.io/v1alpha2 |
- 或者手动创建Certificate资源
1 | # cert.yaml |
- 使用参考Kubernetes Dashboard
- 常见问题
- https网站在浏览器上仍然提示不安全,查看证书路径为
Fake LE Root X1 -> Fake LE Intermediate X1 -> dashboard.k8s.aezo.cn,说明letsencrypt的环境为测试环境,Fake LE Intermediate X1为测试环境CA,参考:https://letsencrypt.org/zh-cn/docs/staging-environment/ - 进入pod查看nginx-ingress-controller的nginx.conf配置发现ssl_certificate和ssl_certificate_key都为
/etc/ingress-controller/ssl/default-fake-certificate.pem;,这个只是一个占位为了让nginx不产生警告,实际nginx-ingress-controller是使用的动态ssl,通过lua脚本实现(对应参数ssl_certificate_by_lua_block) - 查看cert-manager容器日志,提示
server misbehaving,通过busybox测试pod发现容器无法访问外网 - 提示
dial tcp: lookup dashboard.k8s.aezo on 10.96.0.10:53: no such host,将自定义域名的解析加入到corndns对应的configmap - 清除谷歌证书缓存:访问
chrome://net-internals/#hsts,在Delete domain security policies中输入域名删除证书,然后重新打开浏览器
- https网站在浏览器上仍然提示不安全,查看证书路径为
ingress-nginx
https://hub.kubeapps.com/charts/stable/nginx-ingress (基于kubernetes维护的ingress-nginx仓库实现)
1 | helm repo update |
开启TCP/UDP代理(暴露相应服务)
- 参考:https://kubernetes.github.io/ingress-nginx/user-guide/exposing-tcp-udp-services/
- 说明:Ingress默认只能代理http,nginx却可以代理http/tcp/udp
- 配置参考上文的
tcp和controller.service.nodePorts.tcp。具体可参考stable/nginx-ingress中的chart文件 创建成功后,生成nginx.conf中如下
1
2
3
4
5
6
7
8
9
10
11
12
13stream {
# ...
# TCP services
server {
preread_by_lua_block {
ngx.var.proxy_upstream_name="tcp-monitoring-cat-2280";
}
listen 9000;
proxy_timeout 600s;
proxy_pass upstream_balancer;
}
}
Kubernetes Dashboard
1 | ## 提前创建tls类型的secret,名称为k8s-dashboard-tls。否则无法访问,会显示`default backend - 404`。下文 kubernetes-dashboard.yaml 配置中使用 certmanager 自动创建证书 |
- kubernetes-dashboard.yaml
1 | image: |
nfs-client-provisioner
https://hub.kubeapps.com/charts/stable/nfs-client-provisioner
- nfs默认无法自动申请PV;在对应命名空间安装nfs-client-provisioner,则会自动申请并创建PV
- nfs服务器设置如
rw,sync,no_subtree_check,no_root_squash,如果不设置成no_root_squash会导致像基于Chart安装mysql会失败(无法修改文件所属者)
1 | ## 安装 |
Prometheus
- Prometheus相关参考prometheus
1 | helm repo update |
Grafana
- 安装
1 | # kubectl create secret generic grafana-secret -n monitoring --from-literal=admin-user=admin --from-literal=admin-password=Hello1234 |
- 使用
- 增加数据源,数据源地址如
http://prometheus-server.monitoring.svc.cluster.local - 具体参考Grafana
- 增加数据源,数据源地址如
- 常见问题
- 管理面板会随机出现有些请求不成功,提示502,grafana日志显示
http: proxy error: dial tcp: lookup prometheus-server.monitoring.svc.cluster.local: no such host。参考 ^4- 在6.4版中,Grafana将其基本映像从Ubuntu切换到了Alpine,从而部分机器会出现DNS解析失败的问题。因此从Grafana 6.5开始,他们提供了两个图像,一个基于Alpine,另一个基于Ubuntu。https://github.com/linkerd/linkerd2/pull/4600#issuecomment-645012122
- 解决方案(使用方法一解决成功):(1) 增加
GODEBUG: netdns=go的环境变量,可强制使用go DNS解析器而不是OS的解析器,参考上文yaml文件 (2) 或者换成Ubuntu的镜像
- 管理面板会随机出现有些请求不成功,提示502,grafana日志显示
Prometheus Blackbox Exporter
参考:https://hub.kubeapps.com/charts/stable/prometheus-blackbox-exporter
- 网络异常/性能监控,常见的是http_get,http_post,tcp,icmp监控模式
- 安装 ^3
1 | cat > prometheus-blackbox-exporter-values.yaml << 'EOF' |
Postgresql
1 | cat > postgresql-values.yaml << 'EOF' |
数据迁移(成功)
- ceph存储使用说明
- 基于helm部署,如果删除helm-release则会与原PV关联断开,即使重新部署也会产生新的PV
- 如果仅仅删除pod,则原PV是继续使用的(RS会重新创建)
- 数据迁移
1 | ## 备份数据到新pv(此处将文件整体备份,还可导出数据库配置进行备份) |
Redis
1 | cat > redis-values.yaml << 'EOF' |
- 数据迁移(试用)
- 备份master数据到新pv(如果是ceph创建的pv可先进行映射、创建文件系统、临时挂载,然后复制原数据到新pv)
- 增加
persistence.existingClaim参数指向新的创建好的pvc(master会使用此pvc),因此master无需指定master.persistence.storageClass,但slave仍需指定slave.persistence.storageClass - 重新创建chart,在创建master-pod时提示
Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix <filename>- 先将pod启动参数设置成
sleep 1h进行调试 - 进入pod后,先执行
cp data/appendonly.aof data/appendonly.aof.bak,然后执行redis-check-aof --fix data/appendonly.aof输入Y进行AOF文件修复(一般为redis突然掉电导致aof文件损坏,此前由于直接删除原pod导致) - 还原pod原始启动参数并重新启动
- 先将pod启动参数设置成
- 测试时数据貌似有丢失?? 0.0
MongoDB
https://github.com/bitnami/charts/blob/master/bitnami/mongodb/README.md
1 | helm repo add bitnami https://charts.bitnami.com/bitnami |
Harbor
https://hub.kubeapps.com/charts/harbor/harbor 、 https://www.qikqiak.com/post/harbor-quick-install/
1 | ## 安装(访问上述仓库需要梯子,可考虑下文源码安装) |
- 数据库初始化语句如
1 | create database harbor_registry; |
- 命令行镜像推送参考:http://blog.aezo.cn/2017/06/25/devops/docker/
说明
此版本支持docker registry和helm charts仓库。其功能类似开源项目chartmuseum
- 可单独创建一个仓库来放charts或将charts放在每个项目中,如此处单独创建harbor项目charts
上传chart
- 进入charts项目,在Helm Charts标签页下,可以上传chart压缩包(注意需要是使用.tar或.tar.gz压缩文件,rar是不可以的)
或者通过命令上传
1
2
3
4
5
6# 添加helm push命令
helm plugin install https://github.com/chartmuseum/helm-push
# 将对应charts仓库添加到helm。其中用户名和密码为harbor账号,且此账户要有charts仓库的权限;此处charts是指上述的harbor项目名
helm repo add myrepo https://xx.xx.xx.xx/chartrepo/charts --username <username> --password <password>
helm push test-1.0.0.tar.gz myrepo # 推送镜像到仓库
出现过一次异常:upgrade后,导致harbor-harbor-jobservice和harbor-harbor-chartmuseum的历史副本集无法自动删除,导致新的副本集提示启动失败(占用了pvc),可手动删除历史副本集解决
- 常见问题
- 日志提示
failed to initialize database: register db Ping default, pq: could not open file "base/16384/2601": Read-only file system,原因可能为postgresql无法正常访问;且发现集群中postgresql正常运行,但是通过其他桌面客户端无法连接,报类似错误。解决:通过重新创建postgresql容器解决
- 日志提示
Jenkins
1 | ## 安装 |
- 说明
- 多次部署更新jenkins,历史安装的插件不会丢失。如果删除部署后重新部署,会重新创建新PV
- jenkins pod重启创建需要初始化,初始化会安装插件(可在日志-初始容器copy-default-config查看安装日志)。此过程耗时较长,测试时达到40分钟(可使用插件的国内镜像)
- 会默认安装插件Kubernetes:可基于k8s创建agent,即构建时会自动创建子pod(slave节点,镜像jenkins/jnlp-slave),workspace目录则保存在执行任务的slave节点上,当构建完成后会自动删除子pod(包括任务的工作空间)。更多参考jenkins)
- 默认安装的插件配置:/var/jenkins_home/plugins.txt
- 容器中jenkins数据目录为
/var/jenkins_home
ELK
elasticsearch+kibana
1 | helm repo add bitnami https://charts.bitnami.com/bitnami |
- 说明
- elasticsearch-master 的容器初始化会自动执行
sysctl -w vm.max_map_count=262144 && sysctl -w fs.file-max=65536 - k8s中对应的elasticsearch服务地址
http://elasticsearch-monitoring-coordinating-only.monitoring.svc.cluster.local:9200
- elasticsearch-master 的容器初始化会自动执行
logstash
1 | cat > logstash-values.yaml << 'EOF' |
OpenLDAP
- 使用参考LDAP
Nexus(未测试)
https://hub.kubeapps.com/charts/sonatype/nexus-repository-manager
1 | helm repo add sonatype https://sonatype.github.io/helm3-charts/ |
skydive(网络分析)
- 官网
- Skydive 是一款开放式源代码的实时网络拓扑和协议分析器,并可通过WEB界面展示
- Skydive agent,运行在各个节点上,捕捉该节点的拓扑和流量信息。会占用每个节点的8081端口,如果访问http://192.168.6.131:8081可访问此节点的网络拓扑
- Skydive analyzer,收集所有agents捕获的信息
1 | # ibm仓库(skydive测试版) |
- 管理端界面使用
- Filter 过滤网络。基于
Gremlin语法,参考:http://skydive.network/documentation/cli、http://tinkerpop.apache.org/gremlin.html、http://tang.love/2018/11/15/gremlin_traversal_language/G.V()获取所有节点级别网络G.V().Has("Manager",NE("k8s"))获取docker级别(Manager != k8s)网络拓扑
- Filter 过滤网络。基于
Go template语法
简介
基本
- 基本
1 | {{/* comment */}} |
- 管道符
|(类似unix)。helm-chart中常使用|-载入配置文件(|-后面按照原配置文件书写,不用考虑yaml格式)
1 | {{ .Values | quote }} // 等价于 `quote .Values` |
数据类型
1 | {{ $how_long := (len "output") }} // 定义变量 |
控制语句
- if
1 | {{if exp}} T1 {{end}} |
- with 按条件设置 . 值
1 | // 当exp不为0值时,点"."设置为exp运算的值,并执行T1;否则跳过 |
- range、index
1 | // range循环来遍历map(将所有k-v依次展示) |
其他
- 模板嵌套
1 | {{ define "module_name" }}content{{ end }} //声明 |
- 内置函数
Charts
toYaml
1 | # 示例1 |
参考文章
