Linux网络
brctl网桥操作
- 集线器、网桥、交换机、路由器、网关等术语参考 ^12
brctl网桥操作
1 | yum install -y bridge-utils |
ip信息/路由信息
ip aip信息ip a/ip addr可以查看网卡的ip、mac等,即使网卡处于down状态,也能显示出网卡状态,但是ifconfig查看就看不到ip addr show eth0查看指定网卡eth0的信息- 显示结果中作用域说明:
scope {global|link|host}]- global: 全局可用,即两个接口进来的数据都可以响应,是默认状态
- link: 仅链接可用,进来的数据只有直接相连的那个接口能够响应
- host: 本机可用,即只能自己访问
ip r路由信息- 查看路由信息
ip r/ip route; route也可显示路由信息1
2
3
4
5
6
7
8ip r # 显示如下
# 表示去任何地方,都发送给网卡eth0,并经过网关192.168.17.103发出;metric 100表示路由距离,到达指定网络所需的中转数
default via 192.168.17.103 dev eth0 proto static metric 100
# 表示发往 172.16.0.0/16 这个网段的包,都由网卡docker0发出,src 172.17.0.1为网卡docker0的ip
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.0.0/16 dev br-190a4d9330bd proto kernel scope link src 172.18.0.1
192.168.17.0/24 dev eth0 proto kernel scope link src 192.168.17.73 metric 100
- 查看路由信息
ip rule路由策略信息 ^5ip link链路层信息(看不到ip地址)
curl/wget测试
- curl命令
1 | curl [options] [URL...] |
- curl案例
1 | # GET请求 |
ping
1 | # 只向192.168.1.1发送1个包 |
arp
- ARP:地址解析协议(Address Resolution Protocol),其基本功能为透过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。它是IPv4中网络层必不可少的协议,不过在IPv6中已不再适用,并被邻居发现协议(NDP)所替代
- ARP表:设备通过ARP解析到目的MAC地址后,将会在自己的ARP表中增加IP地址到MAC地址的映射表项,以用于后续到同一目的地报文的转发
arp -a查看地址表
DNS查询
dig
1 | yum install bind-utils # 安装dig工具 |
nslookup
1 | # type可以是:A、CNAME、MX、NS、TXT等(默认为A记录);如果没指定dns-server,用系统默认的dns服务器 |
tcpdump
yum -y install tcpdump- 命令参数
1 | # yum -y install tcpdump |
- 示例说明
1 | ## 监控arp(每ping 一次会产生一个arp寻址报文,尽管网桥等设备已经保存了mac地址,也存在此报文) |
traceroute/tracert
traceroute/tracert程序的主要目的是获取从当前主机到目的主机所经过的路由,其中tracert为windows的命令 ^11- 官方方案(TCP/IP详解里提供的基于 UDP 的方案)
- 通过封装一份 UDP 数据报(指定一个不可能使用的端口,30000以上),依次将数据报的 TTL 值置为 1、2、3…,并发送给目的主机
- 当路径上第一个路由器收到 TTL 值为 1 的数据报时,首先将该数据报的 TTL 值减 1,发现 TTL 值为 0,而自己并非该数据报的目的主机,就会向源主机发送一个 ICMP 超时报文,traceroute 收到该超时报文,就得到了路径上第一台路由器的地址
- 然后照此原理,traceroute 发送 TTL 为 2 的数据报时,会收到路径上第二台路由器返回的 ICMP 超时报文,记录第二台路由器的地址
- 直到报文到达目的主机,目的主机不会返回 ICMP 超时,但由于端口无法使用(但是存在正好该端口可使用的情况,只是可能性较小),就会返回一份端口不可达报文给源主机,源主机收到端口不可达报文,证明数据报已经到达了目的地,停止后续的 UDP 数据报发送,将记录的路径依次打印出来,结束任务
- 目的主机端口号最开始设置为 33435,且每发送一个数据报加 1,可以通过命令行选项来改变开始的端口号
- TTL说明
- TTL是数据包的发送主机设置的,发送主机指的是ping后面IP对应的主机(ping返回的TTL是指接收到响应数据包的TTL)。一般linux服务器为64,windows服务器为128,一般设置为255以下数值
- TTL每经过一个路由器或代理服务器都会减1,如果TTL=0则中间路由设备或目的主机都会扔掉此包
iptables
- man-docs、相关文章:洞悉linux下的Netfilter&iptables
- iptables其实不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过iptables这个代理,将用户的安全设定执行到对应的安全框架(如:netfilter)中,这个安全框架才是直正的防火墙。netfilter位于内核空间,iptables位于用户空间
- iptables的规则存储在内核空间的信息包过滤表中,这些规则分别指定了源地址、目的地址、传输协议(如TCP、UDP、ICMP)和服务类型(如HTTP、FTP和SMTP)等。当数据包与规则匹配时,iptables就根据规则所定义的方法来处理这些数据包,如放行(accept)、拒绝(reject)和丢弃(drop)等。配置防火墙的主要工作就是添加、修改和删除这些规则
链(规则)类型:
PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING。每种链类型上可能会有多个规则 ^1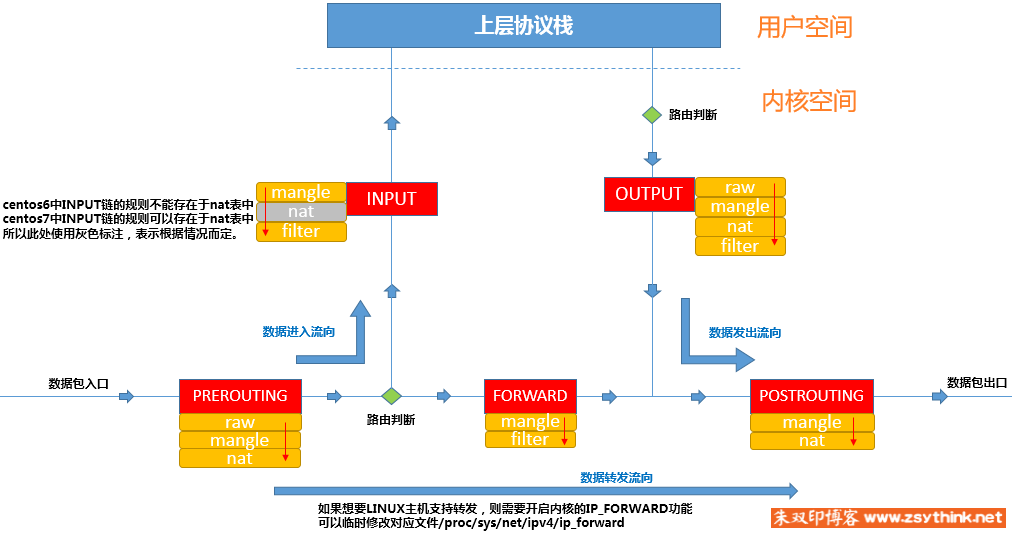
- 流入本机:PREROUTING –> INPUT–> 用户空间进程(本地套接字)
- 转发(本机程序间):PREROUTING –> FORWARD –> POSTROUTING
流出本机(通常为响应报文):用户空间进程 –> OUTPUT–> POSTROUTING
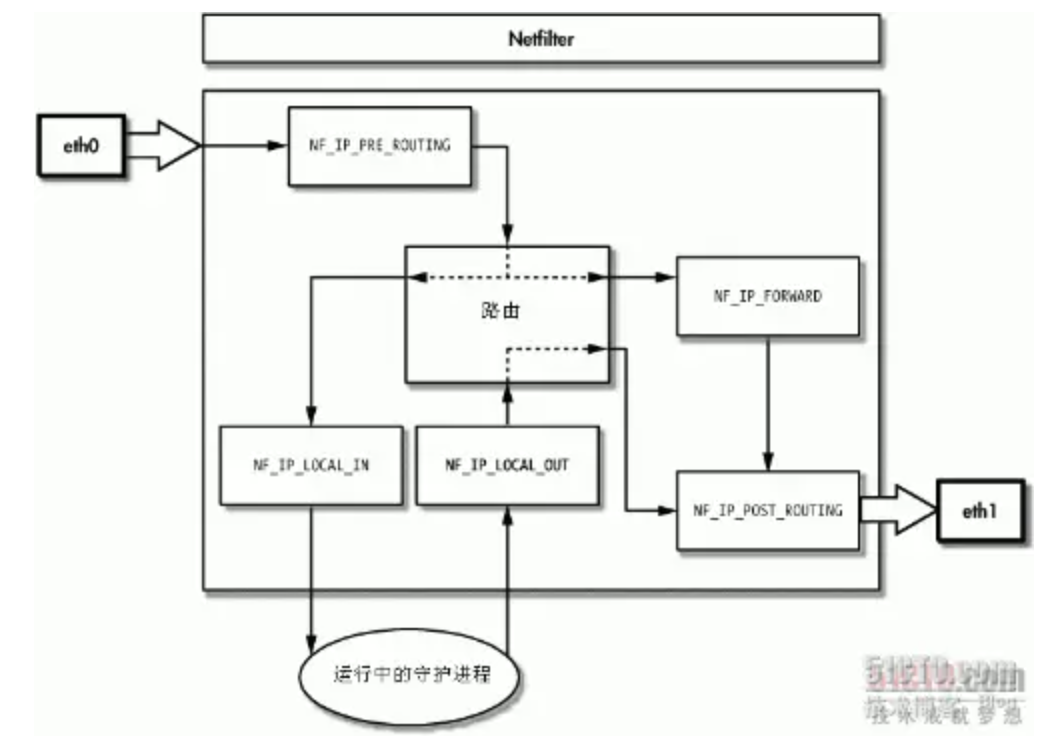
整个chain是从prerouting入,到postrouting出
- input和output都是针对运行中的监听进程而言,不是网卡,也不是主机
- 数据包到路由,路由通过路由表判断数据包的目的地。如果目的地是本机,就把数据包转给intput。如果目的地不是本机,则把数据包转给forward处理,通过forward处理后,再转给postrouting处理
- 表:把具有相同功能的规则的集合叫做”表”,不同功能的规则可以放置在不同的表中进行管理。当他们处于同一条”链”时,执行的优先级为:raw > mangle > nat > filter
raw表:关闭nat表上启用的连接追踪机制;iptable_raw。可能被PREROUTING,OUTPUT使用mangle表:拆解报文,做出修改,并重新封装的功能;iptable_mangle。可能被PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING使用nat表:network address translation,网络地址转换功能;内核模块:iptable_nat。可能被PREROUTING,INPUT,OUTPUT,POSTROUTING(centos6中无INPUT)使用filter表:负责过滤功能,防火墙;内核模块:iptables_filter。可能被INPUT,FORWARD,OUTPUT使用
- 规则由匹配条件和处理动作组成
- 匹配条件:源地址Source IP,目标地址 Destination IP,和一些扩展匹配条件
- 处理动作target
ACCEPT:允许数据包通过(后续规则继续执行。此时会继续校验此链上的其他规则和剩余其他链规则)DROP:直接丢弃数据包,不给任何回应信息,过了超时时间才会有反应。或者出现ping永远无返回信息即卡死(后续不执行)REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息(后续不执行)SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题(后续规则继续执行;只能在nat中使用)MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上(只能在nat中使用)PNAT:源端口转换DNAT:目标地址转换(只能在nat中使用)REDIRECT:在本机做端口映射(只能在nat中使用)LOG:在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配RETURN:结束在目前规则链中的过滤程序,返回主规则链继续过滤。如果把自定义链看成是一个子程序,那么这个动作就相当于提早结束子程序并返回到主程序中(此自定义链后续规则不执行,主链继续执行)QUEUE:防火墙将数据包移交到用户空间TTL:操作TTL(只能在mangle中使用)TRACE:跟踪记录日志(只能在raw表中使用)
- 列出iptables表规则 ^2
1 | ## 列出iptables表规则 |
- 操作iptables规则 ^3
1 | ## 参考:https://blog.csdn.net/qq_38892883/article/details/79709023 |
- 暂存和恢复iptables规则
iptables-save > /etc/sysconfig/iptables暂存所有规则到文件中iptables-restore < /etc/sysconfig/iptables将文件中暂存的规则恢复到规则表中
firewalld
- 决定能否访问到服务器,或服务器能否访问其他服务,取决于
服务器防火墙和云服务器后台管理的安全组- 云服务器一般有进站出站规则,端口开放除了系统的防火墙也要考虑进出站规则
- Centos7默认防火墙为
firewalld,代替了原来的iptables- 防火墙路由规则使用firewall-cmd命令进行维护(也可使用iptables添加);如果需要使用原来的iptables服务,则需要安装iptables-services才能使用(此时可使用
systemctl start iptables启动),但是两个服务只需要启动一个
- 防火墙路由规则使用firewall-cmd命令进行维护(也可使用iptables添加);如果需要使用原来的iptables服务,则需要安装iptables-services才能使用(此时可使用
1 | # 查看状态 |
- /etc/firewalld/zones/public.xml
1 | xml version="1.0" encoding="utf-8" |
ebtables
- ebtables、man-docs
ebtables和iptables^13- 都是linux系统下netfilter的配置工具,可以在链路层和网络层的几个关键节点配置报文过滤和修改规则
- ebtables更侧重vlan,mac和报文流量(太网层面);iptables侧重ip层信息,4层的端口信息
- ebtables 就像以太网桥的 iptables。iptables 不能过滤桥接流量,而 ebtables 可以;ebtables 不适合作为 Internet 防火墙
- Netfilter-Packet-Flow
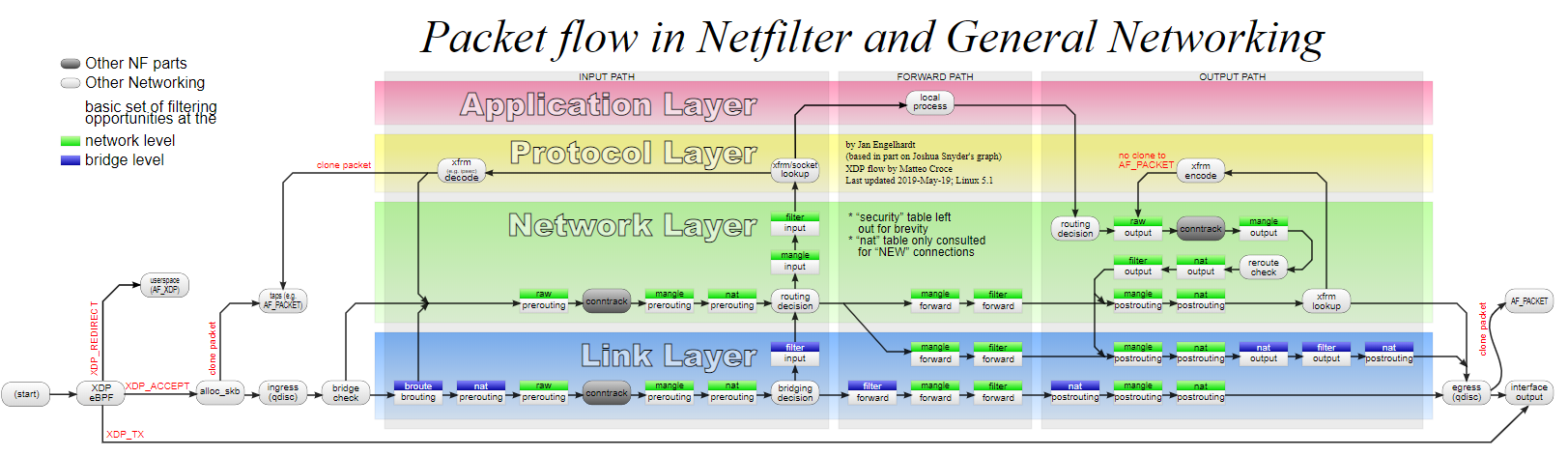
- 使用示例
1 | ebtables # 打印帮助 |
iftop 监控网络带宽使用(基于IP)
1 | ## 安装 |
nethogs 监控网络带宽使用(基于进程)
1 | ## 安装 |
Socket测试(TCP/UDP)
1 | yum install -y nc |
- windows测试工具如SocketTest,可测试TCP/UDP,包含服务端和客户端
网络工具
- Wireshark/Fiddler/Charles
- Wireshark能获取HTTP,也能获取HTTPS,但是不能解密HTTPS。如果是处理HTTP/HTTPS 可使用Fiddler,其他协议比如TCP/UDP就用Wireshark。Wireshark使用也更复杂
- Fiddler不支持Mac,新的Fiddler everywhere需要破解
Charles抓包
- 官网
- 下载5.0后破解(科学上网),如
moon/ef30d3ee8ee17ac30d - 参考: https://www.zhoulujun.cn/html/tools/NetTools/PacketCapture/8908.html
Wireshark抓包
- 参考
- 如果是公网抓包,一般需要选择监听类似以太网的网卡
- 常用表达式
1 | # 监听本机发送给114.114.114.114的包 |
- 表达式字典
- 点击表达式输入框右侧的”表达式”按钮可显示所有支持的表达式(已经分好类)
- 常用的如
IPv4、HTTP2、TCP、UDP、ICMP等。如搜索IPv4或ip.src和定位到相关表达式,右侧会显示此表达式支持的关系类型(==、!=、in、contains等)
网络异常排查案例
TTL=1导致虚拟机/docker无法访问外网
- 前言:公司选择了便宜的网络运营商,导致无论ping那个地址,总是返回TTL=1。直接在公司路由器上测试亦是如此,说明:ping公司内部网络是没有问题的
- 环境介绍:物理机A(192.168.1.72)安装Centos7系统;然后在物理机基于KVM虚拟化出一台虚拟机A1(192.168.122.86),并且基于NAT的方式联网。之前在A上测试过使用桥接模式时,虚拟机A1是可以访问外网的。此测试在之前测试之上完成,因此物理机A上存在一个虚拟网桥br0,其网卡enp6s0是桥接于br0上的;而KVM使用NAT模式时会自动创建一个虚拟网桥virbr0和创建一个虚拟网卡vnet0
- 产生现象
- Linux物理机可正常上网,ping百度返回TTL=1。基于NAT模式,KVM虚拟机无法上网;基于网桥模式创建的docker容器,在docker容器内无法上网。(docker的网桥模式本质是基于iptables进行的NAT转发)
- windows物理机上使用VMware创建Centos7虚拟机B当做上述的宿主机,且在VMware中设置为NAT网络模式,在B中创建KVM虚拟机B1。此时B和B1均可以访问外网;且在B中ping百度返回TTL=128
现象分析
基于NAT模式的KVM虚拟机无法上网
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38### tcpdump监控上述A的几个网卡的icmp包,并在虚拟机A1上ping外网(只发一个包:ping -c 1 114.114.114.114)
## 数据包发送流向:eth0(A1) -> vnet0(A) -> virbr0 -> br0 -> enps60 -> Internet
## 数据包返回流向:eth0(A1) <-- vnet0(A) <-- virbr0 <- br0 <- enps60 <- Internet
## virbr0(tcpdump -i virbr0 -n icmp -vv -e)
# 数据包经过virbr0,之前没有进行过路由转发,因此virbr0受到的数据包TTL=64;此时发现需要转发到br0,因此virbr0会对TTL减1,然后发给br0,因此br0受到的TTL=63
12:58:34.595496 52:54:00:38:ba:c7 > 52:54:00:7f:f7:c3, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 25917, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.122.86 > 114.114.114.114: ICMP echo request, id 14135, seq 1, length 64
## br0(tcpdump -i br0 -n icmp -vv -e)
12:58:34.595557 00:e0:8a:68:01:42 > 00:f1:f5:14:cf:ab, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 25917, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.1.72 > 114.114.114.114: ICMP echo request, id 14135, seq 1, length 64
# 此时TTL=1表示:Internet数据包(返回数据包)到此网卡时,数据包中TTL=1;此时会先将TTL减1后发现TTL值为0,而自己并非该数据报的目的主机,就会向源主机发送一个 ICMP 超时报文
# docker容器从docker0向eth0转发时,到达eth0的TTL也会减少1
12:58:34.804159 00:f1:f5:14:cf:ab > 00:e0:8a:68:01:42, ethertype IPv4 (0x0800), length 98: (tos 0x28, ttl 1, id 16493, offset 0, flags [none], proto ICMP (1), length 84)
114.114.114.114 > 192.168.1.72: ICMP echo reply, id 14135, seq 1, length 64
# 发送 ICMP time exceeded in-transit 超时报文,对应ICMP错误码:TYPE=11,CODE=0/1。并将此错误告知源主机(Internet)
12:58:34.804208 00:e0:8a:68:01:42 > 00:f1:f5:14:cf:ab, ethertype IPv4 (0x0800), length 126: (tos 0xc8, ttl 64, id 18352, offset 0, flags [none], proto ICMP (1), length 112)
192.168.1.72 > 114.114.114.114: ICMP time exceeded in-transit, length 92
(tos 0x28, ttl 1, id 16493, offset 0, flags [none], proto ICMP (1), length 84)
114.114.114.114 > 192.168.1.72: ICMP echo reply, id 14135, seq 1, length 64
## enp6s0(tcpdump -i enp6s0 -n icmp -vv -e)
12:58:34.595571 00:e0:8a:68:01:42 > 00:f1:f5:14:cf:ab, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 25917, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.1.72 > 114.114.114.114: ICMP echo request, id 14135, seq 1, length 64
12:58:34.804159 00:f1:f5:14:cf:ab > 00:e0:8a:68:01:42, ethertype IPv4 (0x0800), length 98: (tos 0x28, ttl 1, id 16493, offset 0, flags [none], proto ICMP (1), length 84)
114.114.114.114 > 192.168.1.72: ICMP echo reply, id 14135, seq 1, length 64
12:58:34.804213 00:e0:8a:68:01:42 > 00:f1:f5:14:cf:ab, ethertype IPv4 (0x0800), length 126: (tos 0xc8, ttl 64, id 18352, offset 0, flags [none], proto ICMP (1), length 112)
192.168.1.72 > 114.114.114.114: ICMP time exceeded in-transit, length 92
(tos 0x28, ttl 1, id 16493, offset 0, flags [none], proto ICMP (1), length 84)
114.114.114.114 > 192.168.1.72: ICMP echo reply, id 14135, seq 1, length 64
## 在本地windows上使用VMware创建Centos7虚拟机B作为宿主机,并使用NAT网络;在B中创建的KVM虚机上ping外网正常。如下为监听宿主机B的br0网卡信息
10:58:15.103187 00:50:56:20:1d:3a > 00:50:56:e2:64:56, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 46399, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.6.10 > 114.114.114.114: ICMP echo request, id 11275, seq 1, length 64
# 此时TTL=128。由此可知同样的环境,只不过是宿主机B的外层还套了一个VMware的控制,右侧可猜想是VMware的NAT模式篡改了此处TTL的值
10:58:15.346226 00:50:56:e2:64:56 > 00:50:56:20:1d:3a, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 128, id 36174, offset 0, flags [none], proto ICMP (1), length 84)
114.114.114.114 > 192.168.6.10: ICMP echo reply, id 11275, seq 1, length 64docker容器内无法上网原因同上,相关分析如下
1
2
3
4
5
6
7
8
9<!-- eth0`为容器网卡,docker0和eth0为宿主机网卡;eth0`和docker0中间基于veth pair进行交互此处省略 -->
1.eth0` -> docker0 触发PREROUTING
2.docker0路由判断:to 114 => docker0 -> !docker0(out) 触发FORWARD
3.访问114:MASQUERADE * -> !docker0 172.17.0.0/16 -> 0.0.0.0/0 触发POSTROUTING
4.路由判断(ip r),访问114:使用eth0访问,192.168.6.10 -> 114
5.114返回处理包:114 -> 192.168.6.10 回执数据从eth0进入(返回)
6.进入PREROUTING阶段,根据连接跟踪系统记录源发送IP为172,114 -> 172.17.0.x
7.路由判断,访问172则基于docker0流入,触发FORWARD
8.之后报文经过POSTROUTING阶段进入容器
- 解决方案:在宿主机A上添加iptables规则,对数据包的TTL进行操作
iptables -t mangle -A PREROUTING -i br0 -j TTL --ttl-inc 10表示数据包从eth0流入则对TTL加10 扩展问题:在宿主机A上安装KVM虚拟机A1,使用桥接网络,然后在虚拟机A1上安装docker,此时A和A1均可访问外网且返回TTL=1,且在容器中无法访问外网
- 按照上述操作当数据包经过A1的eth0网卡时操作TTL值是可以成功让容器上网;但是每当容器重启或者A1重启时,docker都会重写iptables规则(实际是docker会定时重写iptables规则),从而导致自定义规则被覆盖;因此想到一种解决方法是在宿主机A的网卡上操作TTL,但实际失败的,具体原因是默认iptables不对bridge的数据(A和A1基于网桥通信)进行处理,即在网桥上进行转发的并不会触发TTL值的变化,具体参考上文 ebtables#Netfilter-Packet-Flow
解决方案一(操作宿主机A) ^14
1
2
3
4
5
6
7
8
9
10
11
12
13
14vi /etc/sysctl.conf
# 加入下列内容:开启iptables对经过bridge数据的转发,数据每经过网桥设备转发TTL也会减一,此时也可操作TTL。如果net.bridge.bridge-nf-call-iptables=1,也就意味着二层的网桥在转发包时也会被iptables的FORWARD规则所过滤,这样就会出现L3层的iptables rules去过滤L2的帧的问题
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
net.ipv4.ip_forward=1
# 载入指定模块(重启后失效。可设置开机启动,参考linux.md)。防止刷新可能报错:sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file
modprobe br_netfilter
# 刷新
sysctl -p
# 操作宿主机
iptables -t mangle -A PREROUTING -i br0 -j TTL --ttl-inc 10解决方案二(操作宿主机A)
- 此方法如果在虚拟机A1上使用,则docker会定时覆盖iptables规则导致失效。如果场景是直接在宿主机A上安装docker,同理也无法操作宿主机A,此时可以考虑修改上层路由的TTL,或者将宿主机A的docker设置成iptables=false(此时需要手动设置容器网络隔离和访问外网的规则)
保存iptables规则
iptables-save > /etc/sysconfig/iptables(直接保存可能存在其他数据,此处可以手动保存到/etc/sysconfig/iptables)1
2
3
4
5
6
7
8
9
10# Generated by iptables-save v1.4.21 on Thu Jun 20 16:05:03 2019
*mangle
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
-A PREROUTING -i eth0 -j TTL --ttl-inc 10
COMMIT
# Completed on Thu Jun 20 16:05:03 2019将下列脚本加入到开机启动
1
2
3
4
5
6
7
# chkconfig: 2345 50 50
# description: 初始化自定义iptables规则(防止docker覆盖)
# processname: iptables-init
# 基于文件中保存的iptables规则,提交到规则表中
iptables-restore < /etc/sysconfig/iptables
参考文章
