微服务基本介绍
- 架构演进
- 单体架构:复杂度逐渐变高、部署速度慢、阻碍技术创新、无法按需伸缩
- SOA(Service Oriented Architecture) ^1
- 面向服务的架构,他是一种设计方法,其中包含多个服务,服务之间通过相互依赖最终提供一系列的功能,各个服务之间通过网络调用
- SOA中的ESB(企业服务总线),简单 来说 ESB 就是一根管道,用来连接各个服务节点。为了集成不同系统,不同协议的服务,ESB 做了消息的转化解释和路由工作,让不同的服务互联互通
- 微服务(架构选型说明见下文)
- 其实和 SOA 架构类似,微服务是在 SOA 上做的升华,微服务架构强调的一个重点是”业务需要彻底的组件化和服务化”,原有的单个业务系统会拆分为多个可以独立开发、设计、运行的小应用。这些小应用之间通过服务完成交互和集成
- 微服务特点
- 微服务可独立运行在自己的进程里
- 一系列独立运行的微服务构成整个系统
- 每个服务独立开发维护
- 微服务之间通过REST API或RPC等方式通信
- 去中心化:每个微服务有自己私有的数据库持久化业务数据;每个微服务只能访问自己的数据库,而不能访问其它服务的数据库;某些业务场景下,需要在一个事务中更新多个数据库。这种情况也不能直接访问其它微服务的数据库,而是通过对于微服务进行操作
- 优点:易于开发和维护,启动快,技术栈不受限制,按需伸缩,DevOps
- 挑战:
- 最终一致性(各个服务的团队,数据也是分散式治理,会出现不一致的问题)
- 运维测试复杂性,分布式的复杂性,接口调整成本高
- 微服务设计原则:单一职责原则、服务自治原则、轻量级通信原则、接口明确原则
- 微服务开发框架:
Spring Cloud、Dubbo、Dropwizard、Consul等
相关问题
- 微服务架构中如何解决连表查询的问题?
微服务架构选型
- 参考文章:^1
选型示例
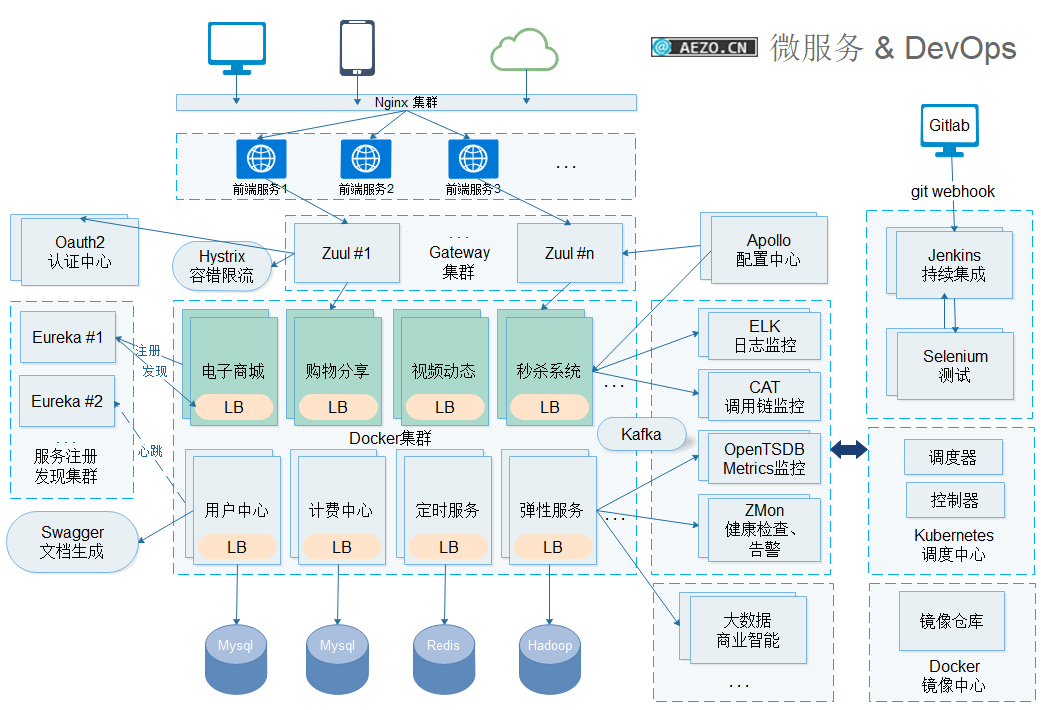
核心支撑组件
服务注册发现
- Eureka
- Netflix Eureka 经过生产级大流量验证的,携程 Apollo 配置中心也是使用 Eureka 做软负载。Eureka 支持跨数据中心高可用,但它是 AP 最终一致系统,不是强一致性系统
- 其它产品如 Zookeeper/Etcd/Consul 等,都是比较通用的产品,还需要进一步封装定制才可生产级使用
- nacos 阿里开源
服务网关
- 微服务网关方案调研、微服务网关哪家强?
- Zuul
- Zuul 网关在 Netflix 经过生产级验证,在纳入 Spring Cloud 体系之后,在社区中也有众多成功的应用。Zuul 网关在携程(日流量超 50 亿)、拍拍贷等公司也有成功的落地实践
- Zuul 网关虽然不完全支持异步,但是同步模型反而使它简单轻量,易于编程和扩展,当然同步模型需要做好限流熔断(和限流熔断组件 Hystrix 配合),否则可能造成资源耗尽甚至雪崩效应(cascading failure)
- 其它开源产品像 Kong 或者 Nginx 等也可以改造支持网关功能,但是较复杂门槛高一点
- Kong支持较多插件,如Dashboard插件以及监控插件
认证授权中心
- Spring Security OAuth2
负载均衡
- Ribbon
- 内部微服务直连可以直接走 Ribbon 客户端软负载,网关上也可以部署 Ribbon,这时网关相当于一个具有路由和软负载能力的超级客户端
- Spring Cloud Eureka Client内部自带
服务配置中心
- 主流微服务配置中心对比、Spring Cloud生态的配置服务器最全对比贴
- Apollo
- 携程开源。Apollo 支持完善的管理界面,支持多环境,配置变更实时生效,权限和配置审计等多种生产级功能。Apollo 既可以用于连接字符串等常规配置场景,也可用于发布开关(Feature Flag)和业务配置等高级场景
- Spring Cloud Config
- Spring Cloud Config 为Pivotal自研产品,功能远远达不到生产级,只能小规模场景下用,中大规模企业级场景不建议采用
扩展组件
数据总线
- Kafka
- 最初由 Linkedin 研发并在其内部大规模成功应用,然后在 Apache 上开源的 Kafka,是业内数据总线 (Databus) 一块的标配,几乎每一家互联网公司都可以看到 Kafka 的身影
- 在监控一块,日志和 Metrics 等数据可以通过 Kafka 做收集、存储和转发,相当于中间增加了一个大容量缓冲,能够应对海量日志数据的场景。除了日志监控数据收集,Kafka 在业务大数据分析,IoT 等场景都有广泛应用。如果对 Kafka 进行适当定制增强,还可以用于传统消息中间件场景
- RabbitMQ
限流熔断和流聚合
- Hystrix(结合Turbine)
- Netflix开源的Hystrix已被纳入 Spring Cloud 体系,它是 Java 社区中限流熔断组件的首选
- Turbine是和Hystrix配套的一个流聚合服务,能够对 Hystrix 监控数据流进行聚合,聚合以后可以在 Hystrix Dashboard 上看到集群的流量和性能情况
监控组件
日志监控
- ELK(ElasticSearch/Logstash/Kibana)
- 据称携程是国内 ELK 的最大用户,每日增量日志数据量达到 80~90TB。ELK 一般和 Kafka 配套使用,因为日志分词操作还是比较耗时的,Kafka 主要作为前置缓冲,起到流量消峰作用,抵消日志流量高峰和消费(分词建索引)的不匹配问题
- 创业公司起步期,考虑到资源时间限制,调用链监控和 Metrics 监控可以不是第一优先级,但是 ELK 是必须搭一套的,应用日志数据一定要收集并建立索引,基本能够覆盖大部分 Trouble Shooting 场景(业务,性能,程序 bug 等)
调用链监控
- 一个业务功能可能需要多个服务协作才能实现,一个请求到达服务A,服务A需要依赖服务B,服务B又依赖服务C,甚至C仍需依赖其他服务,形成一个调用链条,即调用链。调用链监控可以更好的追踪问题、根据实际运行情况优化性能或调整系统资源
- 调用链选型之Zipkin,Pinpoint,SkyWalking,CAT对比、各大厂分布式链路跟踪系统架构对比
- CAT,具体参考cat.md
- CAT为大众点评开源。在点评,携程,陆金所,拍拍贷等公司有成功落地案例,因为是国产调用链监控产品,界面展示和功能等更契合国内文化,更易于在国内公司落地
- 优点
- 报表丰富、社区活跃
- 监控粒度为代码级(高于方法级)
- 缺点
- 代码侵入,需要开发进行埋点(可通过拦截器快速监控暴露的URL端点)
- cat系统的定位:logview是cat原始的log采集方式,cat的logview使用的技术是threadlocal,将一个thread里面的打点聚合上报,有一点弱化版本的链路功能,但是cat并不是一个标准的全链路系统,全链路系统参考dapper的论文,业内比较知名的鹰眼,zipkin等,其实经常拿cat和这类系统进行比较其实是不合适的。cat的logview在异步线程等等一些场景下,其实不合适,cat本身模型并不适合这个。在美团点评内部,有mtrace专门做全链路分析
- 使用:深入详解美团点评CAT跨语言服务监控
- Zipkin
- Spring Cloud 支持基于 Zipkin 的调用链监控,Zipkin 最早是由 Twitter 在消化 Google Dapper 论文的基础上研发,在 Twitter 内部有较成功应用,但是在开源出来的时候把不少重要的统计报表功能给阉割了(因为依赖于一些比较重的大数据分析平台),只是开源了一个半成品,能简单查询和呈现可视化调用链,但是细粒度的调用性能数据报表没有开源
- Zipkin UI非常简洁,可以通过如时间、服务名以及端点名称这类查询条件过滤请求
- 优点:代码侵入较少、社区活跃(但中文文档较少)
- 缺点:报表单一,监控粒度为接口级
- Skywalking 国产,Apache顶级项目
- 基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入
- 监控粒度为方法级
- 存储方式ES,H2
- Spring Cloud Sleuth 是针对每个请求的计时统计。可与Zipkin结合使用,即发送追踪统计到Zipkin
- Google Dapper、阿里-鹰眼均未开源
- OpenTracing 基于Google Dapper研发
Metrics监控
Metrics监控说明
- 互联网应用提倡度量驱动开发(Metrics Driven Development),也就是说开发人员不仅要关注功能实现,做好单元测试(TDD),还要做好业务层(例如注册,登录和下单数等)和应用层(例如调用数,调用延迟等)的监控埋点,这个也是 DevOps(开发即运维)理念的体现,DevOps 要求开发人员必须关注运维需求,监控埋点是一种生产级运维需求。而日志分析是一种产生问题事后的静态分析
- Metrics 提供5种基本的度量类型:Gauges, Counters, Histograms, Meters和 Timers
Counter是一个简单64位的计数器,他可以增加和减少。如:请求的个数,结束的任务数, 出现的错误数Gauge是最简单的度量类型,只有一个简单的返回值,他用来记录一些对象或者事物的瞬时值。如:温度Histrogram是用来度量流数据中Value的分布情况,即柱状图,Histrogram可以计算最大/小值、平均值,方差,分位数(如中位数,或者95th分位数)。如:请求持续时间,响应大小Meters是一种只能自增的计数器,通常用来度量一系列事件发生的比率。他提供了平均速率,以及指数平滑平均速率,以及采样后的1分钟,5分钟,15分钟速率Timer是Histogram跟Meter的一个组合,比如要统计当前请求的速率和处理时间
- Metrics 监控产品底层依赖于时间序列数据库(TSDB)
- Grafana 是 Metrics 展示标配,和主流时间序列数据库都可以集成
时间序列数据库
- Prometheus
- 基于GO开发
- SpringBoot Actuator对接Prometheus,并使用 Grafana 实现数据的可视化
- KairosDB vs. OpenTSDB vs. Prometheus
- KairosDB
- KairosDB 一般也和 Kafka 配套使用,Kafka 作为前置缓冲,可以结合Grafana进行展示
- KariosDB 基于 Cassandra,相对更轻量一点,建议中大规模公司采用。如果公司已经采用 Hadoop/HBase,则 OpenTSDB 也是不错选择
- OpenTSDB
- InfluxDB
其他
- Spring Boot Admin监控
- 是一个针对spring-boot的actuator接口进行UI美化封装的监控工具;包含的Spring Boot Admin UI部分使用AngularJs将数据展示在前端
- 在列表中浏览所有被监控spring-boot项目的基本信息,详细的Health信息、内存信息、JVM信息、垃圾回收信息、各种配置信息(比如数据源、缓存列表和命中率)等,还可以直接修改logger的level
告警系统和健康检查
- ZMon
- ZMon 是德国电商公司 Zalando 开源的一款健康检查和告警平台,具备强大灵活的监控告警能力
- ZMon 本质上可以认为是一套分布式监控任务调度平台,它提供众多的 Check 脚本(也可以自己再定制扩展),能够对各种硬件资源或者目标服务(例如 HTTP 端口,Spring 的 Actuator 端点,KariosDB 中的 Metrics,ELK 中的错误日志等等)进行定期的健康检查和告警,它的告警逻辑和策略采用 Python 脚本实现,开发人员可以实现自助式告警。ZMon 同时适用于系统,应用,业务,甚至端用户体验层的监控和告警
- ZMon分布式监控告警系统架构,底层基于KairosDB时间序列数据库
其他
- Zabbix(模板大全)监控、Nagios监控
其他组件
文档生成组件
- Swagger
- 可以使用Swagger创建一份实时更新的RESTful API文档来记录所有接口细节,然后在集成Swagger-ui,将Json信息可视化展示出来
–
参考文章
