ELK简介
- 官网、官方中文文档、docs
ELK平台主要有由ElasticSearch、Logstash和Kiabana三个开源免费工具组成Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等Logstash可以对日志进行收集、过滤,并将其存储供以后使用KibanaKibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志
- elasticsearch-curator,主要用于管理elasticsearch索引和快照
- Curator是有python开发的,之后被elasticsearch合并
Elasticsearch
基础概念
Lucence:一个Jar包,主要用做分词。其集群实现较难维护- ES的
正排索引和倒排索引正排索引是从文档到关键字的映射(已知文档求关键字:doc_id, terms),倒排索引是从关键字到文档的映射(已知关键字求文档:term, doc_ids)- 二者都是在索引创建的时候生成的,会保存在磁盘,如果内存足够大也会保存在内存中
- 倒排索引以字词为关键字进行索引,可查询到这个字词的所有文档,它记录该文档的ID和字符在该文档中出现的位置情况
- 倒排索引存储的数据结构
- 包含关键词的doc list
- 关键词在每个doc中出现的次数(TF:item frequency)
- 关键词在整个索引中出现的次数(IDF:inverse doc frequency)
- 关键词在当前doc中出现的次数
- 每个doc的长度,越长相关度越低
- 包含每个关键词的所有doc的平均长度
- 应用领域
- 百度(全文检索、高亮、搜索推荐)
- 用户行为日志(用户点击、浏览、收藏、评论)
- BI(Business Intelligence商业智能),数据分析,数据挖掘统计
- Github:代码托管平台,几千亿行代码
- ELK:Elasticsearch(数据存储)、Logstash(日志采集)、Kibana(可视化)
- 核心概念
- Field:一个数据字段,与index和type一起,可以定位一个doc
- Document:ES最小的数据单元,JSON格式
- Type:逻辑上的数据分类,es 7.x中删除了type的概念
- Index:一类相同或者类似的doc,不能包含大写字母
- 和传统数据库对比:Document->row,Type->table,Index-db
读写过程及原理
- ES 写数据过程 ^2
- 客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节点)
- coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)
- 实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node
- primary node 和所有 replica node 都写完之后,协调节点就返回响应结果给客户端
- ES 搜索数据过程
- 客户端发送请求到一个 coordinate node
- 协调节点将搜索请求转发到所有对应的 primary shard 或 replica shard
- query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id )返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
- fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端
- ES 读数据过程(基于doc id)
- 客户端发送请求到任意一个 node,这个 node 就是 coordinate node
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡
- 接收请求的 node 返回 document 给 coordinate node
- coordinate node 返回 document 给客户端
- 写入数据底层原理
- 数据先写入内存 buffer(ES进程),并同时写入translog
- 然后每隔 1s或内存 buffer快满了,将数据
refresh到一个新的segment file(中间还是会先写到os cache),到了 os cache 数据就能被搜索到(所以ES为NRT近实时,near real-time,因为中间有 1s 的延迟) translog大到一定程度,或者默认每隔 30min,会触发 commit 操作,将缓冲区的数据都flush到 segment file 磁盘文件中- commit/flush操作过程
- 将buffer中现有数据refresh到os cache中去,清空buffer
- 将一个commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file
- 将os cache数据fsync强刷到磁盘上去
- 清空translog日志文件
- translog其实也是先写入os cache的,默认每隔5秒刷一次到磁盘中去,所以可能会丢失5秒钟的数据
- translog日志作用:在你执行commit操作之前,数据要么是停留在buffer中,要么是停留在os cache中,二者都是内存,一旦这台机器死了,内存中的数据就全丢;而此时重启后可通过translog日志进行恢复
- commit/flush操作过程
- 如果是删除操作,commit的时候会生成一个.del文件,里面将某个doc标识为deleted状态
- 如果是更新操作,就是将原来的doc标识为deleted状态,然后新写入一条数据
- buffer每1秒refresh一次,就会产生一个新的segment file,因此会定期执行
merge,即将多个segment file合并成一个,同时这里会将标识为deleted的doc给物理删除掉,然后将新的segment file写入磁盘
语法
- 字段搜索方式
exact value精确匹配:在倒排索引过程中,分词器会将field作为一个整体创建到索引中full text全文检索:分词、近义词同义词、混淆词、大小写、词性、过滤、时态转换等(normaliztion)
CRUD
1 | ## 索引操作 |
Query DSL
1 | ## https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html |
filter缓存原理
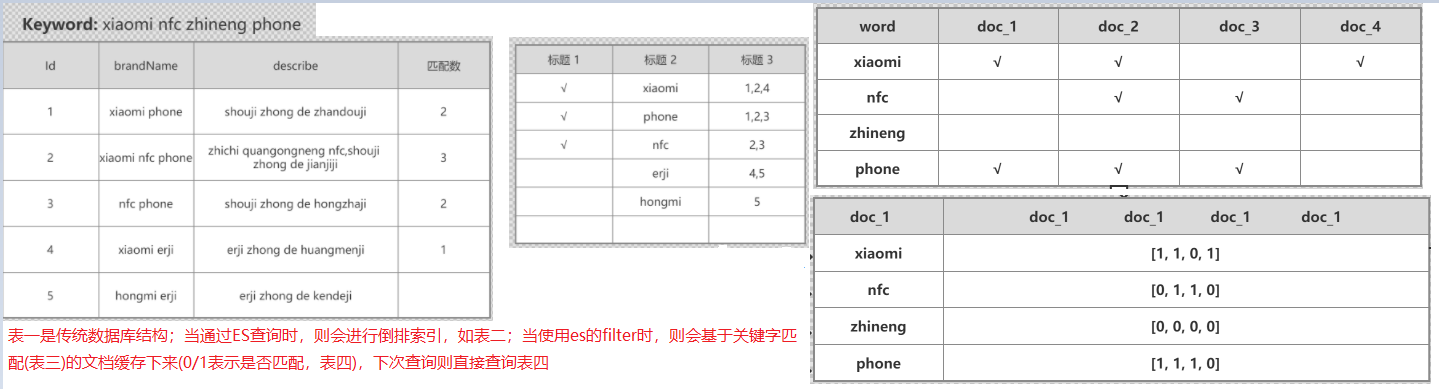
- filter cache保存的是匹配结果,下次查询不需要再从倒排索引中去查找比对,提供了查询速度
- 当filter执行某个查询一定次数(动态变化)时才会进行cache
- filter会优先从稀疏的数据中进行过滤来保存cache数据
- filter一般会在query之前执行,过滤掉一部分数据,从而提供query速度
- filter不计算相关度分数,执行效率较query高
- 当元数据发生变化时,cache也会更新
mapping
mapping定义和dynamic mapping
- mapping定义
- mapping就是字段field的元数据(可理解为MySQL的字段定义)
- ES在创建索引的时候,通过dynamic mapping机制会自动为不同的数据指定相应mapping,当然也可以手动定义mapping
- mapping中包含了字段的类型、搜索方式(exact value或者full text)、分词器等
1 | # 手动创建mappings |
ES数据类型
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
- 核心类型
- 数字类型:long, integer, short, byte, double, float, half_float, scaled_float
- 字符串:keyword、text
- keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。Id应该用keyword
- text:字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项,从而用于全文检索,如产品描述。text类型的字段不用于排序,很少用于聚合(主要是字段数据会占用大量堆空间,加载字段数据是一个昂贵的过程)
- 同一个字段有时可能同时具有text和keyword:一个用于全文本搜索,另一个用于聚合和排序
- 日期:date、date_nanos(ES7 新增)
- 布尔:boolean
- 二进制:binary
- 区间类型:integer_range、float_range、long_range、double_range、date_range
- array:数组。在ES中,数组不需要专用的字段数据类型,默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值都必须具有相同的数据类型
- 复杂类型
- object:用于单个JSON对象
- nested:用于JSON对象数组
- 地理位置
- geo-point:纬度/经度积分
- geo-shape:用于多边形等复杂形状
- 特有类型
- ip:用于IPv4和IPv6地址
- completion:提供自动完成建议
- token_count:计算字符串中令牌的数量
- murmur3:在索引时计算值的哈希并将其存储在索引中
- annotated-text:索引包含特殊标记的文本(通常用于标识命名实体)
- percolator:接受来自query-dsl的查询
- join:为同一索引内的文档定义父/子关系
- rank_features:记录数字功能以提高查询时的点击率
- dense_vector:记录浮点值的密集向量
- sparse_vector:记录浮点值的稀疏向量
- search-as-you-type:针对查询优化的文本字段,以实现按需输入的完成
- alias:为现有字段定义别名
- flattened:允许将整个JSON对象索引为单个字段
- shape:对于任意笛卡尔几何
- histogram:用于百分位数聚合的预聚合数值
- constant_keyword:当所有文档都具有相同值时的情况
Mapping parameters
1 | # 参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html |
doc_values和fielddata- 当字段的doc_values=false,但是又需要聚合时,可打开fielddata,然后临时在内存中创建正排索引(首次查询时生成),fielddata的构建和管理都发生在JVM Heap中
- fielddata使用的是JVM内存;doc_value在内存不足时会保存在磁盘中,只有当内存充足时,才会加载到内存加快查询
- ES采用circuit breaker(熔断)机制避免fielddata一次性超过物理内存大小而导致内存溢出。如果触发熔断,查询会被终止并返回异常
- fielddata默认是false的,因为text字段较长,一般只做分词和索引,很少拿来做聚合排序
Metadata fields元数据字段
_field_names_ignored_id_index_meta_routing_source原始数据_type
aggregations聚合查询
1 | # https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html |
Scripts脚本
- ES脚本语言支持 painless(默认)、expression、mustache、java
- painless:用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,安全的脚本语言
- expression:可以非常快速地执行,甚至比编写native脚本还要快,支持javascript语法的子集:单个表达式。缺点:只能访问数字,布尔值,日期和geo_point字段,存储的字段不可用
- ES 5.0之前还支持Groovy,但是由于其不安全(容易爆内存),被弃用了
- script模板
- 缓存在集群的cache中,作用域为整个集群,只有发生变更时重新编译。没有过期时间,默认缓存大小是100MB,脚本最大64MB
- 可以手工设置过期时间script.cache.expire,通过script.cache.max_size设置缓存大小,通过script.max_size_in_bytes配置脚本大小
doc['field'].value和params['_source']['field']区别- 首先,使用doc关键字,将导致该字段的条件被加载到内存(缓存),这将导致更快的执行,但更多的内存消耗。此外,
doc[...]符号只允许简单类型(不能返回一个复杂类型(json对象或者nested类型)),只有在非分析或单个词条的基础上有意义 _source每次使用时都必须加载并解析,使用_source非常缓慢。因此,doc仍然是从文档访问值的推荐方式
- 首先,使用doc关键字,将导致该字段的条件被加载到内存(缓存),这将导致更快的执行,但更多的内存消耗。此外,
- 案例
1 | ## https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting.html |
集群
- ES集群优点
- 面向开发者友好,屏蔽了Lucene的复杂特性,集群自动发现(cluster discovery)
- 自动维护数据在多个节点上的建立
- 包含搜索请求的负载均衡
- 自动维护冗余副本,保证了部分节点宕机的情况下仍然不会有任何数据丢失
- ES基于Lucene提供了很多高级功能:复合查询、聚合分析、基于地理位置等
- 可以构建几百台服务器的大型分布式集群,处理PB级别数据
- 相比统数据库的有点:提供了全文检索,同义词处理,相关度排名,聚合分析以及海量数据的近实时(
NTR)处理
- Shard分片
- 一个index包含多个Shard,默认5P,默认每个P(primary shrad分片)分配一个R(replica shard副本)。P的数量在创建索引的时候设置,如果想修改,需要重建索引
- 每个Shard都是一个Lucene实例,有完整的创建索引的处理请求能力
- ES会自动在nodes上为做shard均衡
- 一个doc是不可能同时存在于多个PShard中的,但是可以存在于多个RShard中
- P和对应的R不能同时存在于同一个节点,所以最低的可用配置是两个节点,互为主备
ES生产集群部署(基本表)
- ES 生产集群我们部署了 5 台机器,每台机器是 6 核 64G 的,集群总内存是 320G
- 我们 es 集群的日增量数据大概是 2000 万条,每天日增量数据大概是 500MB,每月增量数据大概是 6 亿,15G。目前系统已经运行了几个月(6个月),现在 es 集群里数据总量大概是 100G 左右
- 目前线上有 5 个索引(这个结合你们自己业务来,看看自己有哪些数据可以放 es 的),每个索引的数据量大概是 20G,所以这个数据量之内,我们每个索引分配的是 8 个 shard(比默认的 5 个 shard 多了 3 个 shard)
性能优化
- 增加系统内存
- 无用的字段(不用来做检索的字段)不要保存到es中。可将全量数据保存在mysql/hbase中,通过关键字在es中查询到id,然后去获取相应数据
- 数据预热:就是对热数据(如热销商品、微博大V)每隔一段时间,就提前访问一下,让数据进入内存里面去
- 冷热分离:es 可以做类似于 mysql 的水平拆分,冷数据写入一个索引中,然后热数据写入另外一个索引中
- document 模型设计:先在 Java 系统里就完成关联(复杂的SQL查询),将关联好的数据直接写入 es 中(document 模型存储复杂SQL的结果),尽量避免在es中进行 join/nested/parent-child 等查询
- 分页性能优化:使用scroll search或search_after来防止深度分页
运维
集群信息
_cat信息
1 | ## 查看_cat子路径 |
Logstash
1 | # 测试向Logstash发送数据 |
Kibana
- 文档
- 面板介绍
- Discover:日志管理视图(主要进行搜索和查询)
- Visualize:统计视图(构建可视化的图表)
- Dashboard:仪表视图(将构建的图表组合形成图表盘)
- Timelion:时间轴视图(随着时间流逝的数据)
- APM:性能管理视图(应用程序的性能管理系统)
- Canvas:大屏展示图
- Dev Tools: 开发者命令视图
- Monitoring:健康视图(请求访问性能预警)
- Management:管理视图
- 左上角
CHANGE CURRENT SPACE可切换或管理SPACE(可以理解为一个组),每一SPACE需要自行管理Kibana的Index Patterns和Advanced Settings等
Discover显示
- 需要先创建索引表达式,参考 Management - Kibana设置 - Index Patterns
- New新增查询、Save保存当前查询、Open打开查询、Share分享查询、Inspect
- 左侧可用字段点击”+”会自动显示到右边的(默认显示的是整个文档)
搜索
- KQL语法
- kibana搜索简易指南: https://www.jianshu.com/p/61b53815122b
1 | # 精确查找此单词(单词前后有空格隔开) |
Management
- Elasticsearch设置
- Kibana设置
- Index Patterns 显示的是创建好的索引表达式
- Create index pattern创建索引表达式 - 输入正则匹配现有的索引(如:sq-demo-*) - 可在Discover中查看
- Saved Objects 为保存的Objects,如:配置信息(Advanced Settings)、索引表达式(index pattern)、查询面板(search)、分享短连接
- Advanced Settings
- General
Date format日志时间显示,如:YYYY/MM/DD HH:mm:ss.SSSDay of week没周的第一天,如MondayAdmin email接收异常邮件
- Discover
Default columns定义”发现”标签页上默认显示的列(默认为显示列为_source,即以key:value的格式显示在一起)。此处修改如:spring_application_name,level,thread_name,logger_name,message(基于springboot项目定制,这样会影响全局,不建议修改)
- General
- Index Patterns 显示的是创建好的索引表达式
其他
- Stack Monitoring
- 首次进入 Turn on monitoring 开启ELK服务器磁盘,内存等监控
SpringCloud整合ELK
- Spring Cloud与ELK平台整合使用时,只需要实现与负责日志收集的Logstash完成数据对接即可,且Logstash自身也支持收集logback日志,所有通过在logback配置中增加对logstash的appender,就能非常方便的将日志转换成以json的格式存储和输出了 ^1
基于容器安装
- 基于k8s-helm安装参考:ELK
- 基于docker安装
1 | ## 安装 **Elasticsearch** (下载会较慢,可尝试下载几次) |
Elasticsearch
- 如果想在生产环境下启动,需要将 Linux 核心配置项 vm.max_map_count 设置为不小于 262144 的数
- 查看
more /proc/sys/vm/max_map_count - 设置
sysctl -w vm.max_map_count=262144
- 查看
Logstash
SpringBoot引入依赖
1 | <!-- 参考:https://github.com/logstash/logstash-logback-encoder --> |
logback-spring.xml加入appender
1 | <!-- |
与Kafka结合
https://yq.aliyun.com/articles/645316
测试
- 配置好上述流程后,运行SpringBoot项目
- 进入Kibana面板创建索引表达式
- Management - Stack Management - Kibana - Index patterns(显示的是创建好的索引表达式) - Create index pattern(创建新的所有表达式,可查看到所有的索引)
- 进入Discover查看日志
参考文章
