简介
- TODO
- java应用常见故障:高CPU占用、高内存占用、高I/O占用(包括磁盘I/O、网络I/O、数据库I/O等)
- 高CPU常见场景:死循环(如while导致的较多)、高内存导致
- 高内存占用也会引起高CPU占用:内存溢出后,java的GC便会运行非常频繁,从而导致高CPU(此时可能已经产生了dump文件,但是应用还能访问,只是速度较慢。临时可考虑先重启服务)
- 相关命令参考常用命令介绍:1-4
- 高内存常见场景:List集合数据量过大(常见从数据库获取大量数据,而没有进行分页获取) ^2
java.lang.OutOfMemoryError: PermGen space,原因可能为- 程序启动需要加载大量的第三方jar包。例如:在一个Tomcat下部署了太多的应用
java.lang.OutOfMemoryError: Java heap space,原因可能为- Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整
- 代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)
- 在Java虚拟机中,内存分为三个代
- 新生代New:新建的对象都存放这里
- 老生代Old:存放从新生代New中迁移过来的生命周期较久的对象。新生代New和老生代Old共同组成了堆内存
- 永久代Perm:是非堆内存的组成部分。主要存放加载的Class类级对象如class本身,method,field等等
grep 'OutOfM' * -5
应用服务器故障
常用命令介绍
1 | ## 1.查看linux运行状态(htop工具显示更强大):如8核则CPU可能达到800% |
java检测相关命令工具
1 | # 显示java进程,-l显示完整包名,-m显示传递给main方法的参数,-v显示传递给JVM的参数, |
MAT工具使用/实例分析
- MAT(Memory Analyzer Tool):根据分析dump文件从而分析堆内存使用情况,下载
- 运行jar包时加参数如:
java -jar test.jar -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/jvmlogs,/home/jvmlogs为程序出现内存溢出时保存堆栈信息的文件(需要提前建好) MAT打开类似于
java_pid11457.hprof的堆栈文件(File - Open Heap Dump。右键文件打开可能会失败),需要设置MAT运行的最大内存足够大(设置MemoryAnalyzer.ini),打开效果如下(Leak Suspects Report泄漏疑点报告)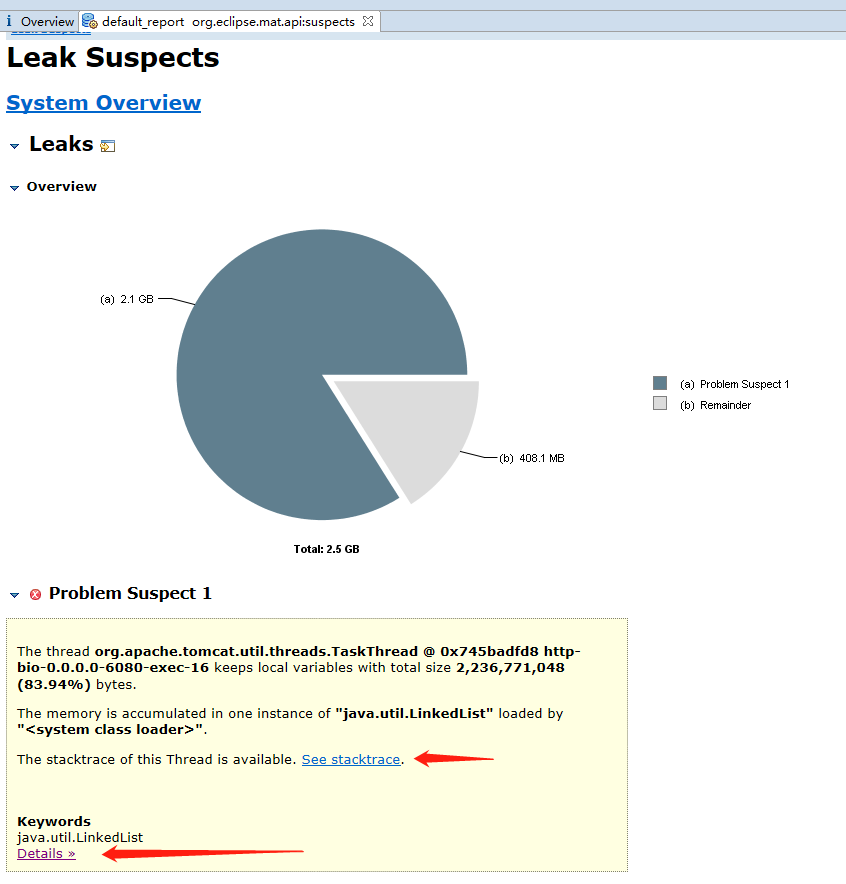
- 从上图的报告中可以看到
bio-0.0.0.0-6080-exec-16有大量的java.util.LinkedList对象(此图片是和下面截图的hprof文件不是同一个)
- 从上图的报告中可以看到
界面说明
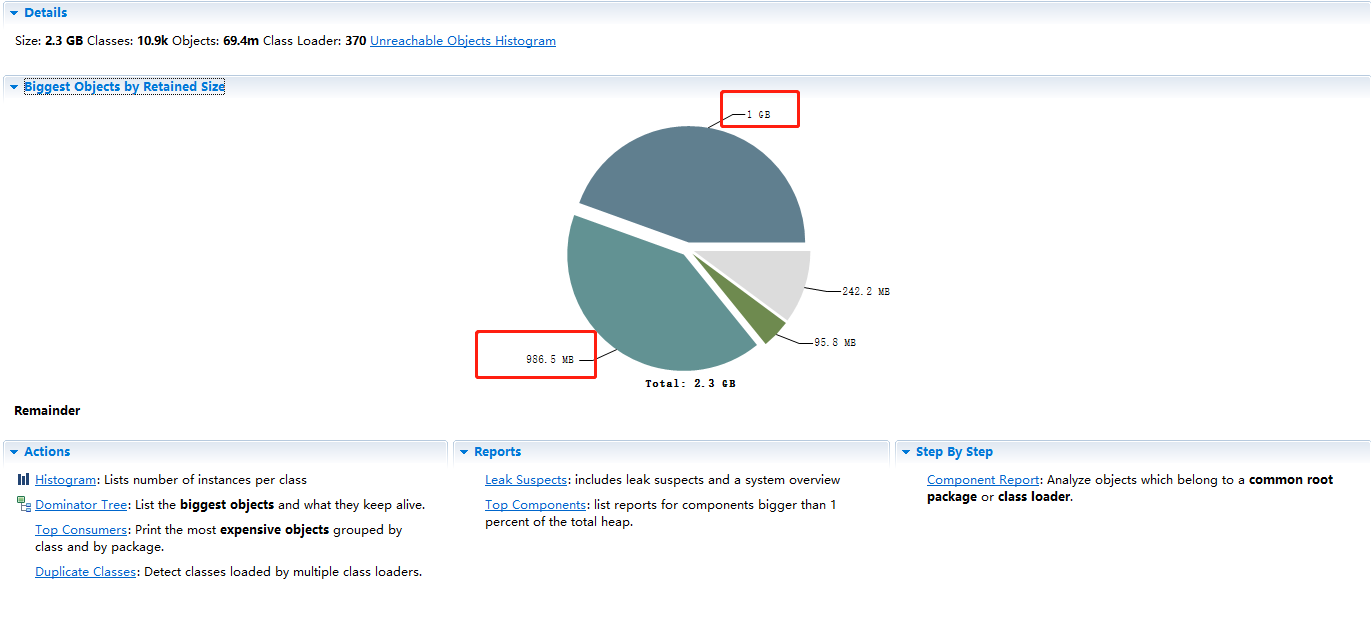
Overview此dump文件分析的控制面板- Details:统计dump大小、类个数(ofbiz-yard正常12k左右)、对象个数、Class Loader个数(ofbiz-yard正常400个左右)
Biggest Objects by Retained Size大对象所占空间分析(饼图)- 白色为未使用
- 其他颜色鼠标悬浮可查看相应的线程主要信息
左键某扇形-Java Basics-Thread Details查看此大对象所在线程信息
Actions常用功能菜单Histogram列举每个class对应实例的数量Dominator Tree列举大对象组成树Top Consumers按照包和类列举大对象Duplicate Classes列举重复的class(多个类加载器加载的同一类文件导致类重复)
Reports报告类型Leak Suspects Report泄漏疑点报告(常用)Top Components列出大于总堆1%的组件的报告
Step By StepComponent Report分析属于一个公共根包或类加载器的对象
具体分析
MAT预览界面
Dominator Tree点击如下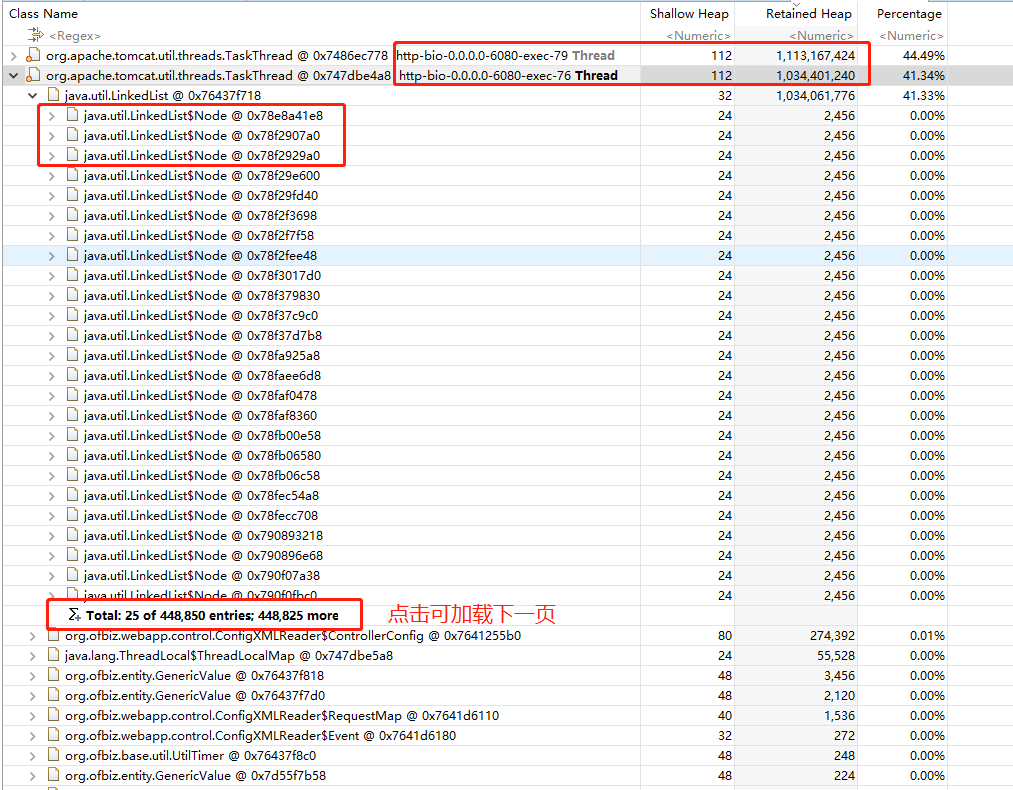
- 从图
mat-dominator-tree中可以发现是存在大量的LinkedList;继续查看此List,结果如mat-dominator-tree2;从中可以发现是查询表YyardVenueMovePlan导致
- 从图
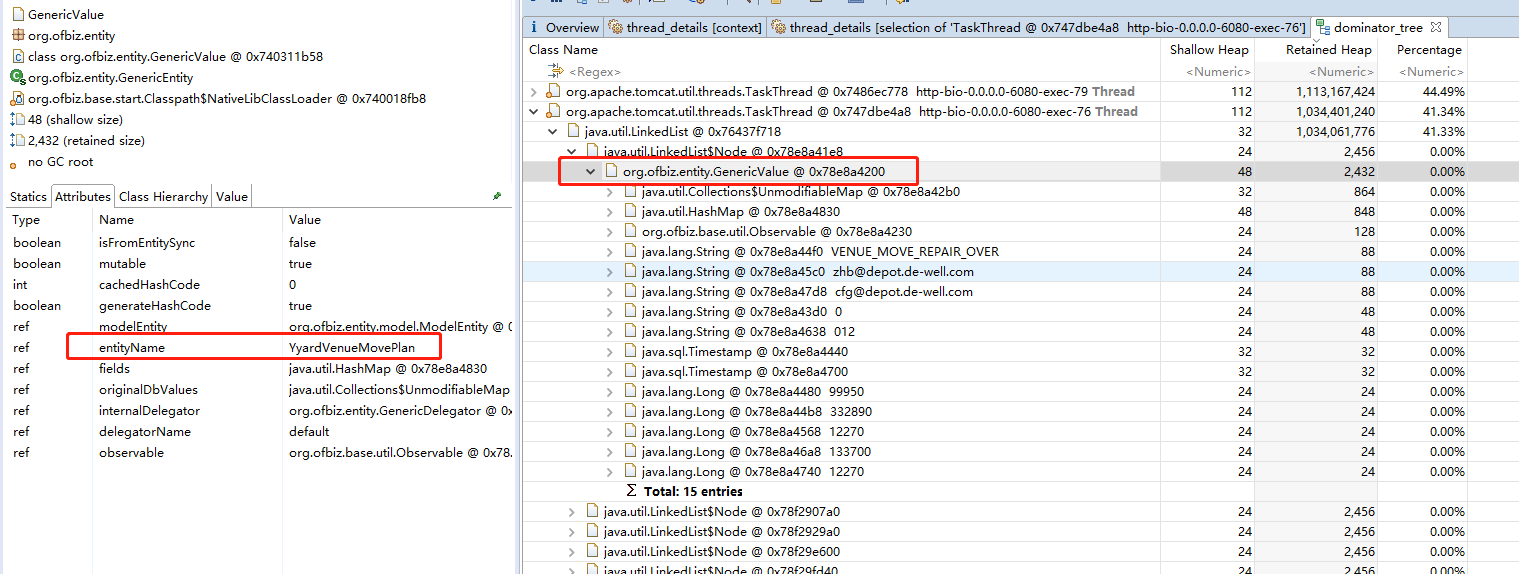
查看堆栈信息(上图中
http-bio-0.0.0.0-6080-exec-76和http-bio-0.0.0.0-6080-exec-79),结果如下图。说明是调用了MovePlan.java中的deleteMovePlan导致出现大量的LinkedList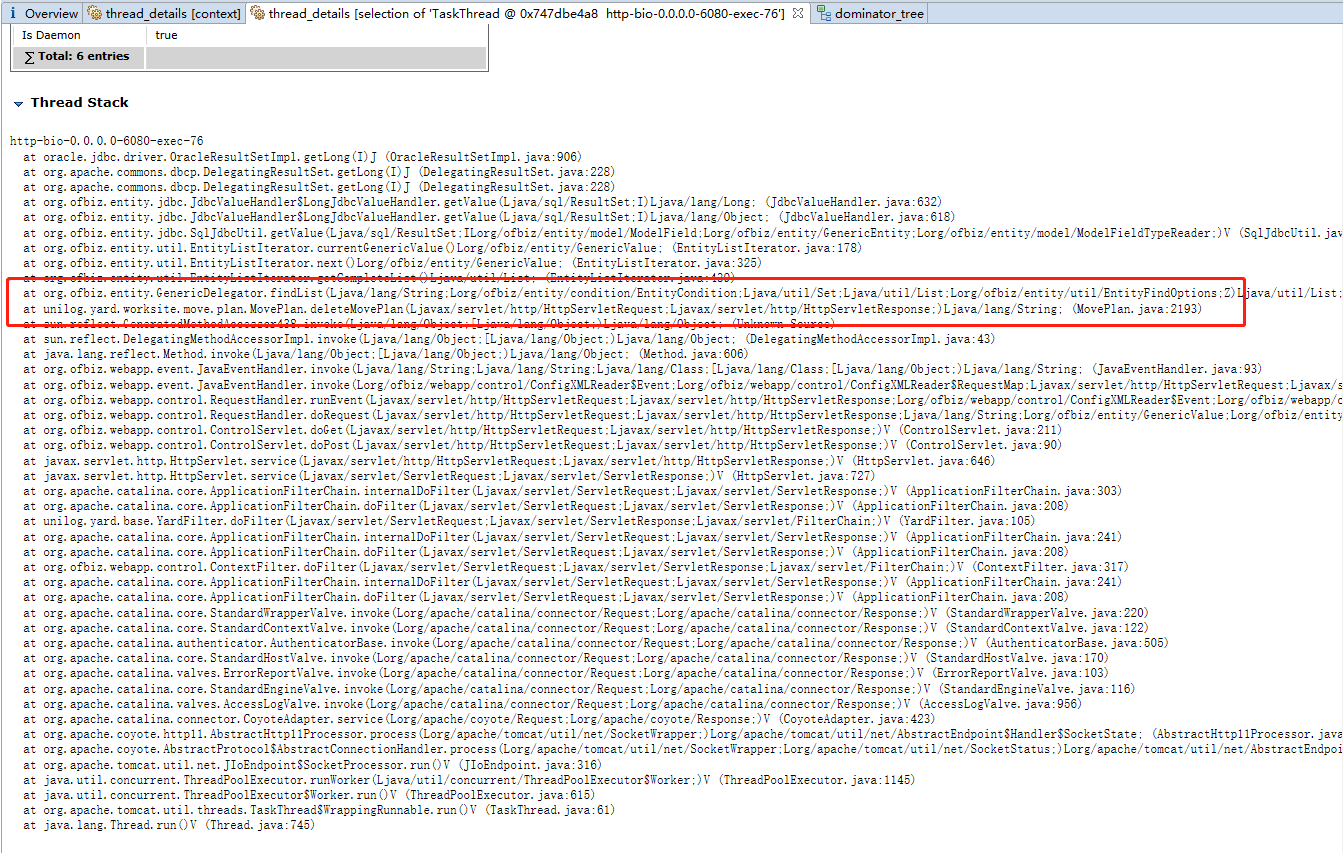
查看对应代码,如下图。由于
YyardVenueMovePlan数据非常大,如果shortBoardId为空(只有短驳计划才会有此字段,因此相当于查询所有非短驳计划),则出现内存溢出。返回去查看LinkedList中的对象,发现shortBoardId字段都为空,验证了上述假设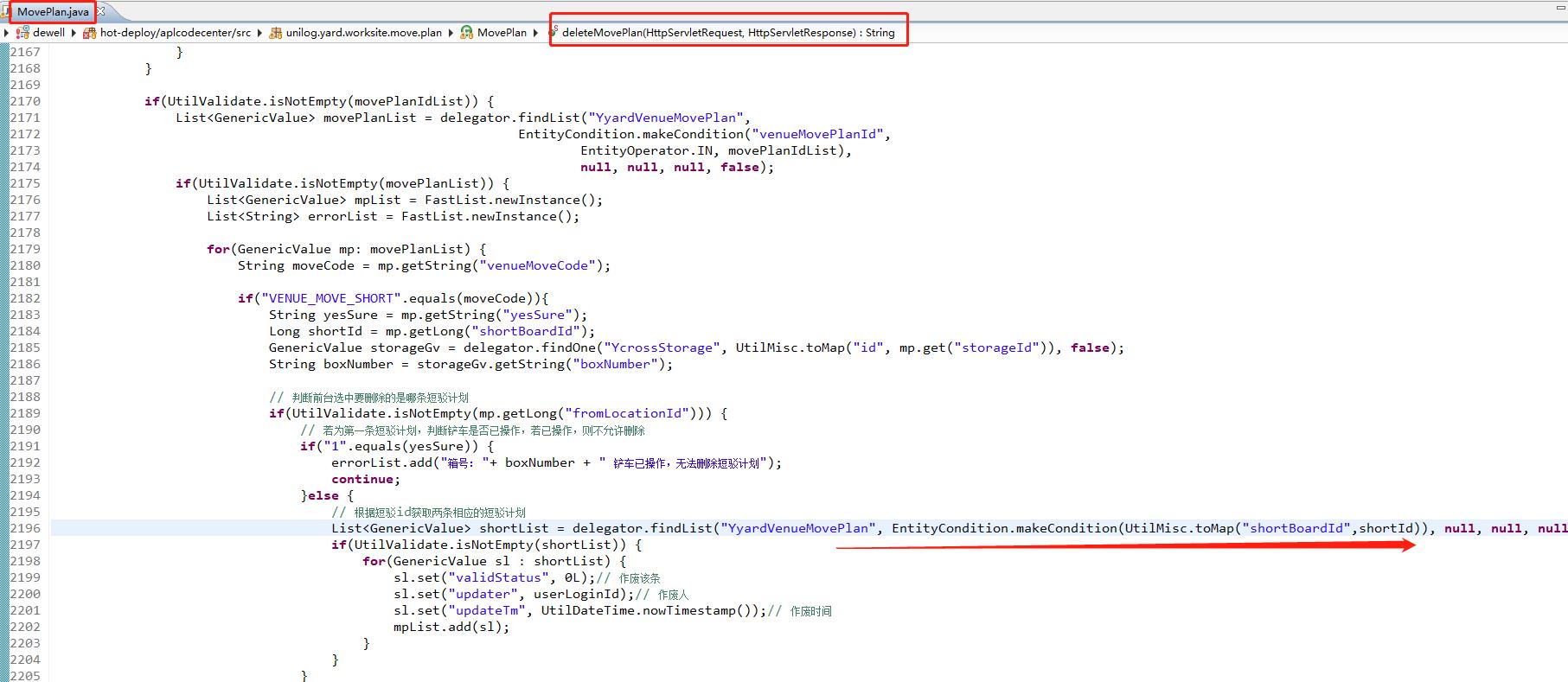
内存飙高,但是下载的dump文件却很小
- 现象:内存占用达到3G,下载的dump文件确只有400M左右(生成dump文件耗时1分钟,生成dump文件时应用无法访问),并未发现内存溢出现象
- 可能原因
-Xmx设置太小
OFBiz项目案例分析
案例介绍:此问题主要是ofbiz在清理历史任务时,任务数据过大导致内存溢出,从而CPU飙升,最终服务器时常宕机。
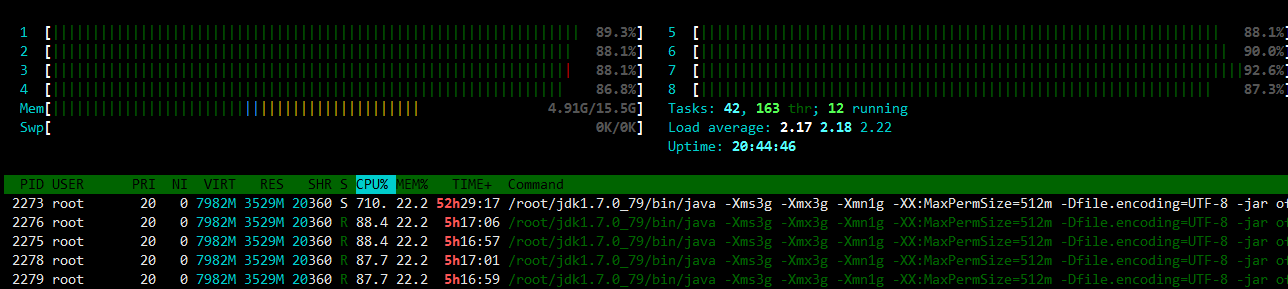
htop查看情况如下
可以看到其中PID=2273的进程CPU占用到达710%(服务器为8核),内存占用22%(服务器为16G*0.22=3.52G,jvm参数设置的内存大小为3G),其中线程运行时间达到5h29m。以上数据说明程序运行存在问题
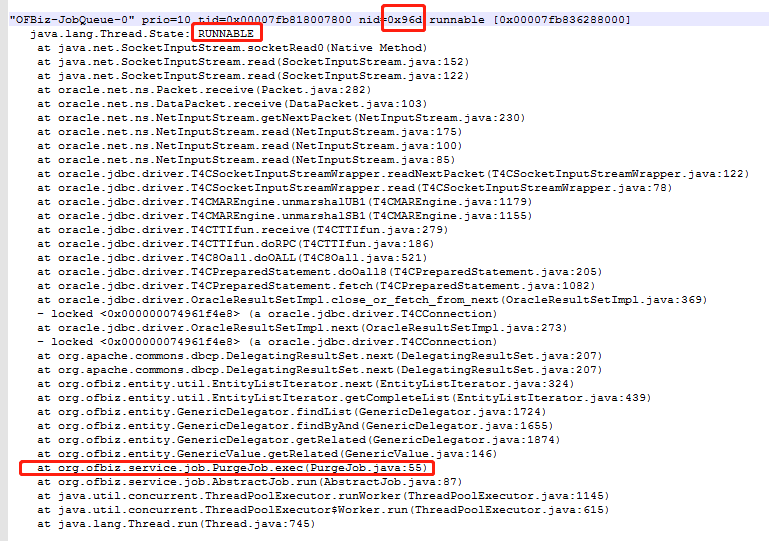
ps -mp 2273 -o THREAD,tid,time,rss,size,%mem查看此进程下线程运行情况:实际中发现有7个进程占用CPU均达到几十分钟,且CPU和内存占用均非常高。(其中2个是ofbiz拉取历史任务进行清理的进程,5个为GC进行垃圾回收的进程)jstack 2273 | grepprintf “%x\n” 2413-A 40查看2273进程下2413线程的堆栈信息如下(或者输出到文件进行查看)
可以看到线程有以下调用信息org.ofbiz.service.job.PurgeJob.exec(PurgeJob.java:55),如是可以去查看PurgeJob的源码。(当然应该多次查看此线程的堆栈,查看一次可能存在偶发性)
- ofbiz的PurgeJob相关源码。详细可参考《OFBiz服务和任务机制》
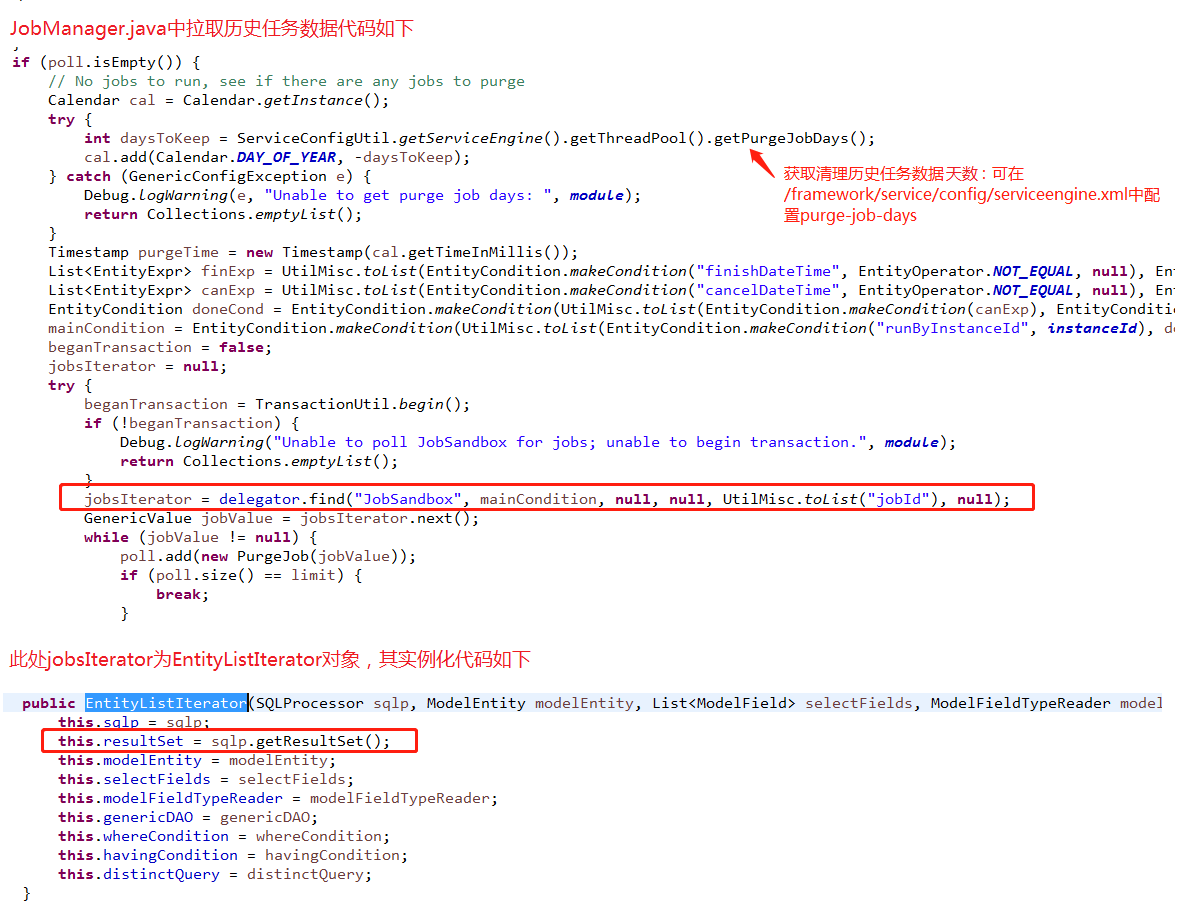
ofbiz任务机制有如下逻辑:当拉取任务线程为获取到需要执行的任务时,则进行历史任务数据(JobSandbox等表数据)清理工作,即获取当前时间4天(默认的purge-job-days)前完成或者取消的任务数据进行删除。
而此处是根据ofbiz实体引擎查询的历史数据放到一个EntityListIterator中进行遍历(查看源码可知本质并没有分页获取数据,而是将所有查询的数据放到ResultSet进行遍历)
由于本项目前期并没有太多的关注任务调用周期,从而导致大量任务堆积,并且不能及时清理。一定数量后,再次触发任务数据清理时就会从数据库获取大量数据到内存,从而内存移除,GC频繁清理,CPU飙升,服务器宕机。
MAT分析:从服务器下载dump文件使用MAT进行分析,发现也可发现上述情况
解决方案
由于个人觉得ofbiz任务机制不太好用,决定不去清理历史数据,而是手动定时清理(或绕过ofbiz定时去清理)。因此可以修改/framework/service/config/serviceengine.xml中purge-job-days的值。重新启动服务器(之前占用的内存无法及时清除,必须重启服务器)和项目一切正常
内存溢出
java.lang.OutOfMemoryError: PermGen space
https://wenku.baidu.com/view/0ae2586b7e21af45b307a8ac.html
关于cglib缓存问题 http://touchmm.iteye.com/blog/1155694 、 https://blog.csdn.net/englishma/article/details/42610545
https://blog.csdn.net/Aviciie/article/details/79281080
相关监测工具
MAT上文已介绍、Jprofile 需要注册
JDK自带
jvisualvm.exe、jconsole.exe类似,下面以jvisualvm.exe为例- 本地连接:直接运行即可选择本地java项目进行监测
远程连接(最好关闭防火墙和安全组设置1-65535的入栈。除了JMX server指定的监听端口号外,JMXserver还会监听一到两个随机端口号,这些端口都必须允许连接)
运行jstatd(可省略)
在JAVA_HOME/bin目录下创建jstatd.all.policy文件,内容如下
1
2
3grant codebase "file:${java.home}/../lib/tools.jar" {
permission java.security.AllPermission;
};$JAVA_HOME/bin/jstatd -J-Djava.security.policy=jstatd.all.policy运行jstatd
- 运行项目时添加JMX参数,如:
java -Djava.rmi.server.hostname=101.1.1.1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.port=5005 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar video-0.0.1-SNAPSHOT.jar --spring.profiles.active=prod - 添加JMX连接 - 输入
101.1.1.1:5005即可
数据库服务器故障
- CPU故障展现 ^4
- 数据库服务器CPU飙高
- oracle相关进程CPU占用高
- 应用服务器响应很慢
Oracle
- 查看数据库sql运行占用CPU时间较长的会话信息,并kill此会话
1 | -- 获取每次消耗cpu > 3s的sql; last_call_et为当前会话执行时间; cpu_time为占用cpu微秒数; executions执行次数; client_identifier为客户端id(java可全局动态更新成当前用户) |
查看服务器CPU占用高较高的进程运行的sql语句(v$sqltext中的sql语句是被分割存储),运行下列sql后输入进程pid
top查看占用CPU较高的进程,Commad中可以看到连接数据的命令信息,如oracleorcl (LOCAL=NO)为OFBiz的连接信息1
2
3
4
5
6
7
8
9
10
11-- 其中&pid是使用top查看系统中进程占用CPU极高的PID (pl/sql中执行运行,会弹框输入pid)
select sql_text
from v$sqltext a
where (a.hash_value, a.address) in
(
select decode(sql_hash_value, 0, prev_hash_value, sql_hash_value),
decode(sql_hash_value, 0, prev_sql_addr, sql_address)
from v$session b
where b.paddr = (select addr from v$process c where c.spid = '&pid')
)
order by piece asc
其他异常问题
1 | -- 查询被锁表的信息(多刷新几次,应用可能会临时锁表) |
- 常用查询
1 | -- 列出数据库里每张表的记录条数 |
Mysql
- 参考:https://juejin.cn/post/6945726594702901261
show full processlist;查看进程(Time的单位是秒)show processlist;查看进程快照查看进程详细
1
2
3
4
5
6
7
8
9-- command: 显示当前连接的执行的命令,一般就是休眠或空闲(sleep),查询(query),连接(connect)
-- time:线程处在当前状态的时间,单位是秒
-- state:显示使用当前连接的sql语句的状态,很重要的列。state只是语句执行中的某一个状态,一个 sql语句,以查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成
-- 查询正在执行,且基于耗时时间降序
select id, user, host, db, command, time, state, info
from information_schema.processlist
where command != 'Sleep'
and time > 30
order by time desc;查询执行时间超过2分钟的线程,然后拼接成 kill 语句。复制出来手动运行
1
2
3
4
5
6
7-- kill 15667;
-- 生成查杀sql
select concat('kill ', id, ';')
from information_schema.processlist
where command != 'Sleep' and info like 'SELECT%'
and time > 2*60
order by time desc;
MySQL出现
Waiting for table metadata lock的原因以及解决方法。常出现在执行alter table的语句,如修改表结构的过程中(线上风险较高) ^1show processlist;长事物运行,阻塞DDL,继而阻塞所有同表的后续操作。(kill #id)select * from information_schema.innodb_trx;未提交事物,阻塞DDL (kill #trx_mysql_thread_id)- 查询到上述情况线程ID进行查杀
show open tables where in_use > 0;查看正在使用的表(锁表)
SqlServer
1 | -- 查看运行中的sql,根据耗时降序排列 |
JVM调优实践及相关案例
JVM致命错误日志
- 当JVM发生致命错误导致崩溃时,会生成一个hs_err_pid_xxx.log这样的文件,该文件包含了导致 JVM crash 的重要信息
- 该文件默认生成在工作目录下的,可通过JVM参数指定
-XX:ErrorFile=/var/log/hs_err_pid<pid>.log - 日志分析 ^5
- 此处由于java的Java_java_util_zip_Deflater_deflateBytes(相关的还有Java_java_util_zip-xxx等方法)调用了系统libzip的相关方导致。由java堆栈可以看出在渲染FTL时,tomcat会进行文件压缩再返回给用户,从而调用了系统的libzip相关方法
- 此案例解决办法:关闭tomcat压缩,使用nginx压缩。ofbiz关闭压缩方法:设置
framework/catalina/ofbiz-component.xml文件参数catalina-container.http-connector.compression=off
1 | # ##################### 日志头文件 |
参考文章
