简介
Hadoop([hædu:p])作者Doug cutting,名字来源于Doug Cutting儿子的玩具大象- 模块
HDFS(Hadoop Distributed File System) 分布式存储系统Hadoop MapReduce分布式计算框架Hadoop YARN资源管理系统(Hadoop 2.x才有)Hadoop Common
- 网址
- 谷歌论文(理论来源)
- 《The Google File System》 2003年
- 《MapReduce: Simplified Data Processing on Large Clusters》 2004年
- 《Bigtable: A Distributed Storage System for Structured Data》 2006年
- 版本:2016年10月hadoop-2.6.5,2017年12月hadoop-3.0.0
- 大数据生态CDH提供商
HDFS
HDFS基础概念
- HDFS优缺点
- 优点:高容错性(自动保存副本,自动恢复)、适合批处理、适合大数据(TB/PB)处理、可构建在廉价机器上
- 缺点:占用内存大、修改文件成本过高
- 存储模型
- 文件线性按字节切割成块(block),具有offset,id
- 文件与文件的block大小可以不一样
- 一个文件除最后一个block,其他block大小一致
- block的大小依据硬件的I/O特性调整
- block被分散存放在集群的节点中,具有location
- block具有副本(replication),没有主从概念,副本不能出现在同一个节点。副本是满足可靠性和性能的关键
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入,多次读取,不支持修改
- 支持追加数据
- 数据块/数据存储单元(Block)说明
- 文件被切分成固定大小的数据块,数据块默认大小为128MB(Hadoop 1.x默认为64M,后来发展为256M,可调整)。若文件大小不到128MB,则单独存成一个Block
- 一个文件存储方式:按大小被切分成若干个Block,存储到不同节点上。默认情况下每个Block都有三个副本
- block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可以变更,Block Size不可变更
- 架构设计
- HDFS是一个主从(Master/Slaves)架构
- 由一个NameNode和一些DataNode组成
- 面向文件,包含:文件数据(data)和文件元数据(metadata)
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block的读写
- DataNode与NameNode维持心跳,并汇报自己持有的block信息
- Client和NameNode交互文件元数据和DataNode交互文件block数据
- 角色功能
NameNode(NN)- NameNode主要功能
- 完全基于内存存储文件
metadate元数据、目录结构、文件block的映射- 需要持久化方案保证数据可靠性,持久化方案为 fsimage 和 edits 结合(类似redis的镜像日志和普通日志)
- 提供副本放置策略
- 接受客户端的读写服务
- 完全基于内存存储文件
- NameNode的metadate信息说明
- 元数据信息存储形式为
fsimage和editsfsimagemetadata存储到磁盘文件名为fsimage(format格式化的时候产生)edits记录对metadata的操作日志(客户端读写日志),会自动合并到fsimage中- 以上两个文件主要记录了文件包含哪些block,block保存在哪个DataNode(由DataNode启动时上报)
- NameNode的metadate信息在启动后会加载到内存
- Block的位置信息不会保存到fsimage(NN将block位置存放到内存中)
- 元数据信息存储形式为
- NameNode主要功能
DataNode(DN)- 基于本地磁盘存储Block(文件的形式)
- 并保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
- 启动DN线程的时候会向NN汇报block信息(NN将block位置存放到内存中)
- 通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其它DN
SecondaryNameNode(SNN, 非HA模式才有)- 它不是NN的备份,也不是HA,它的主要工作是帮助NN合并edits日志,减少NN启动时间
- SNN执行合并时机:根据配置文件设置的时间间隔
fs.checkpoint.period默认3600秒;根据配置文件设置edits日志大小fs.checkpoint.size规定edits文件的最大值默认是64MB。超过时间或到达日志大小则合并
- 元数据持久化
- NameNode使用了FsImage(镜像) + EditLog(日志)整合的方案。类似redis的持久化方式
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当Namenode启动时,它从硬盘中读取Editlog和FsImage
- 将所有Editlog中的事务作用在内存中的FsImage上
- 并将这个新版本的FsImage从内存中保存到本地磁盘上
- 然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了
- NameNode使用了FsImage(镜像) + EditLog(日志)整合的方案。类似redis的持久化方式
- 安全模式
- Namenode启动后会进入一个称为安全模式的特殊状态
- 处于安全模式的Namenode是不会进行数据块的复制的
- Namenode从所有的 Datanode接收心跳信号和块状态报告
- 每当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全(safely replicated)的
- 在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的30秒等待时间),Namenode将退出安全模式状态
- 接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他Datanode上
- Block的副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点
- 第二个副本:放置在与第一个副本不同机架的节点上
- 第三个副本:与第二个副本相同机架的节点
- 更多副本:随机节点
读写流程
写流程
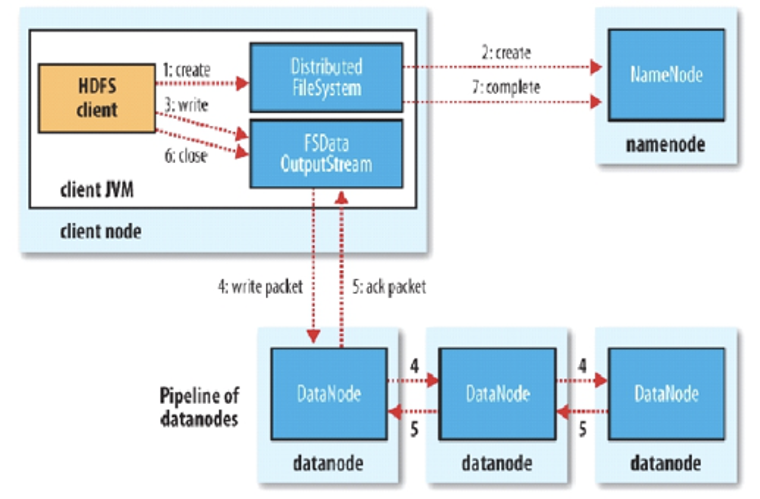
- Client和NN连接创建文件元数据
- NN判定元数据是否有效
- NN触发副本放置策略,返回一个有序的DN列表
- Client和DN建立Pipeline连接
- Client将块切分成packet(64KB),并使用chunk(512B)+ chucksum(4B)填充
- 基于流式传输数据,其实也是变种的并行计算
- Client将packet放入发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存并发送给第二个DN,此时第一个DN可以接收下一个packet
- 第二个DN收到packet后本地保存并发送给第三个DN
- 当block传输完成,DN们各自向NN汇报,同时client继续传输下一个block,client的传输和block的汇报也是并行的
读流程
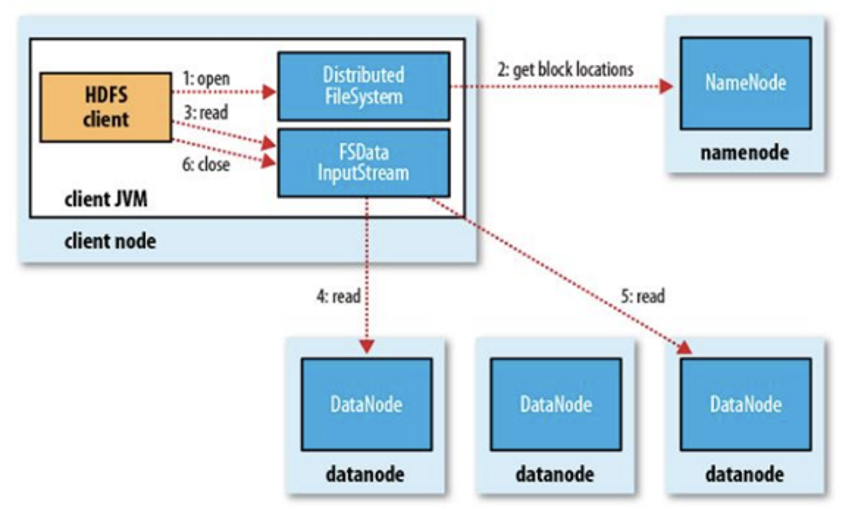
- 为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本
- 如果读取程序的本机上,则直接读取本机
- 如果在读取程序的同一个机架上有一个副本,那么就读取该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
- 语义:下载一个文件
- Client和NN交互文件元数据获取fileBlockLocation
- NN会按距离策略排序返回
- Client尝试下载block并校验数据完整性
- 语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
- HDFS支持client给出文件的offset自定义连接哪些block的DN,自定义获取数据
- 这个是支持计算层的分治、并行计算的核心
- 为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本
HA及联邦
- 解决HDFS 1.0中单点故障和内存受限问题
- 解决单点故障:HDFS HA(通过多个主备NameNode解决)
- 如果主NameNode发生故障,则切换到备NameNode上(备NameNode会同步主NameNode元数据)
- 所有DataNode同时向两个NameNode汇报数据块信息
- 解决内存受限问题:HDFS Federation(联邦)
- 水平扩展,支持多个NameNode
- 每个NameNode分管一部分目录。直接在A NN中无法获取B NN的目录结构,可以在两个NN之上再创建一个统一目录管理,如/a目录保存到A NN,/b保存到B NN
- 所有NameNode共享所有DataNode存储资
- 解决单点故障:HDFS HA(通过多个主备NameNode解决)
- 基于Zookeeper自动切换方案(也可手动切换)
Zookeeper Failover Controller(ZKFC) 监控NameNode健康状态,并向Zookeeper注册NameNode。NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active
HA架构图
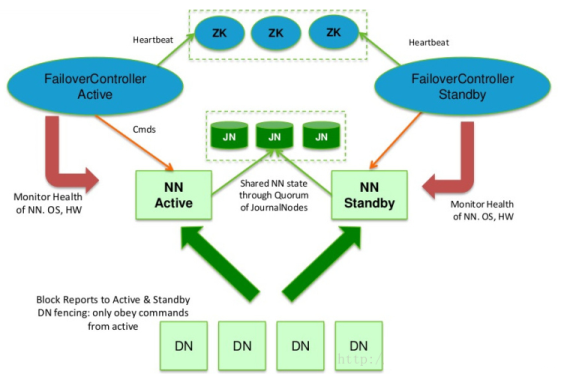
NameNode分为Active(主)和Standby(备)。主备切换的条件是两天NN的元数据一致NameNode(Active)会将edits文件保存到JournalNode中(服务数>=2)。NameNode(Standby)会同步JournalNode中的edits数据。初始化时,将其中一台进行fsimage格式化,然后将此fsimage复制到其他机器。确保元数据(fsimage + edits)一致- 所有DataNode启动时同时向两个NameNode汇报数据块信息
Zookeeper Failover Controller和NameNode是一一对应。作用:通过远程命令控制NameNode切换;对NameNode做健康检查,并汇报给Zookeeper
Federation架构图
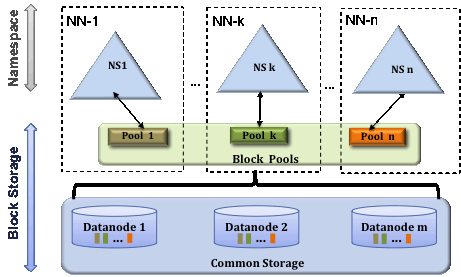
- 通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器来进行水平扩展。多个namenode相会独立
- 能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中
MapReduce
- Map-reduce的思想就是”分而治之”
- 主要分为
Map和Reduce两个阶段- Map和Reduce是阻塞的,必须先完成Map阶段才可进入Reduce阶段,这种计算方式属于批量计算(不同于流式计算)
- Map负责映射、变换、过滤;Reduce负责分解、缩小、归纳;二者通过KV关联,并根据K分组
- 也可细分为
Split、Map、Shuffler(sort、copy、merge)、Reduce几个阶段
Map-Reduce整体架构图
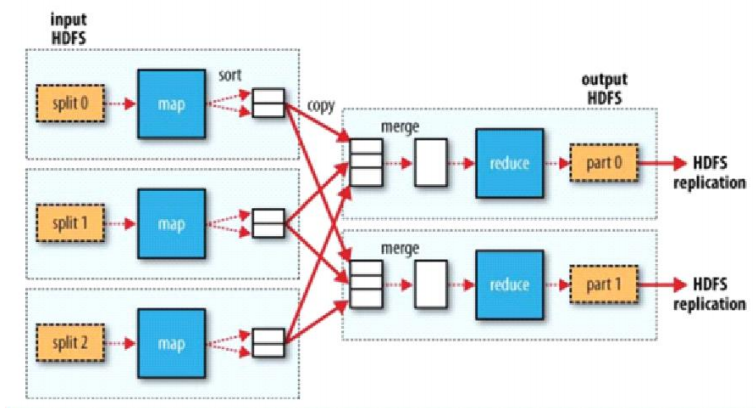
- 从split块中以一条记录为单位,执行map方法映射成KV;相同的key为一组,这一组数据调用一次reduce方法,在方法内迭代计算这一组数据
- 数据按照一定的切割规律提交到每个Map进程中
- block是物理切割,split是逻辑切割(可根据资源情况,设置切割大小),默认对应Block大小
- 有说切割大小为
max(min.split, min(max.split, block))其中默认min.split=10M,max.split=100M,block=128M
- reduce计算使用迭代器模式:数据集较大时,使用迭代的计算方式,可有效节省内存(只需要获取一条数据到内存中进行计算)
MapTask-ReduceTask执行原理
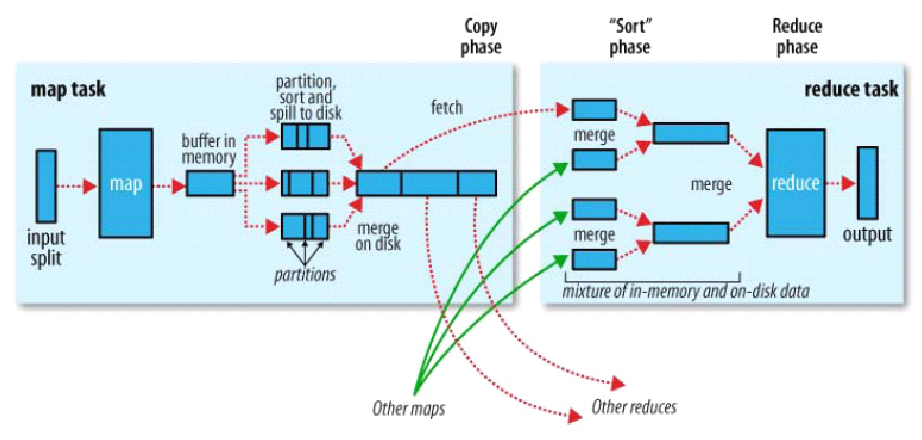
- MapTask流程
- split切片会格式化出记录(如以换行符或开闭标签等方式来进行切割),以记录为单位调用map方法
- map的输出映射成KV,KV会参与分区计算,拿着key算出分区号P(如按照reduce个数取模),最终为K,V,P
- 将上述单条记录处理好后保存到buffer中,buffer满后按照分区P和键K进行快速排序,然后按照归并排序写入到一个本地文件中(最终得到的文件是先按分区排,分区内按照K排)
- 使用buffer是为了减少IO,如果每次将单条记录写入到文件中会频繁产生IO(系统调用)
- 按分区排好序是方便后面ReduceTask读取MapTask结果文件时只需读取一部分(分区部分),不用扫描整个文件
- 按K排好序也是方便后面ReduceTask计算时使用迭代器模式,不用扫描整个分区片段
- ReduceTask流程
- 从不同MapTask中获取结果文件,读取当前ReduceTask处理的分区片段
- 将几个分区片段按照归并排序合并后提交到Reduce方法中进行迭代计算
- reduce的归并排序其实可以和reduce方法的计算同时发生
- 且无需将所有片段合并到文件再计算,从而减少IO,因为有迭代器模式的支持
- 将计算结果输出
- MapTask流程
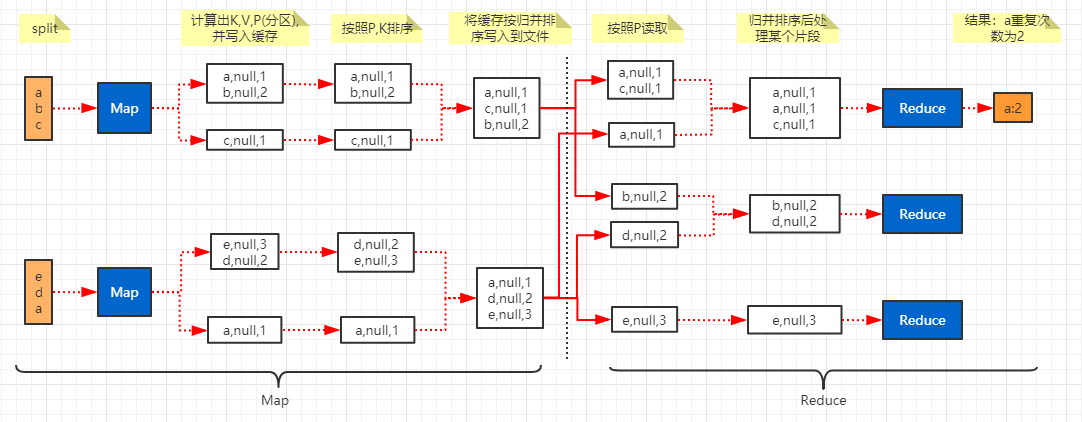
执行流程举例(查询文件中的重复行)
YARN
- 由于MapReduce注重计算向数据移动(将计算用到的算法程序拷贝到数据所在节点执行,减少数据IO),而一份数据一般会有几个备份,且集群中可能同时运行着多个任务,因此需要资源管理(考量节点CPU/内存/网络等因素)来协调运行计算的节点
- YARN是Haddop 2.x才出现的集群资源管理独立模块,只要是Hadoop生态均可使用;最早资源管理系统是集成在MapReduce中的
Haddop 1.x
MR资源管理
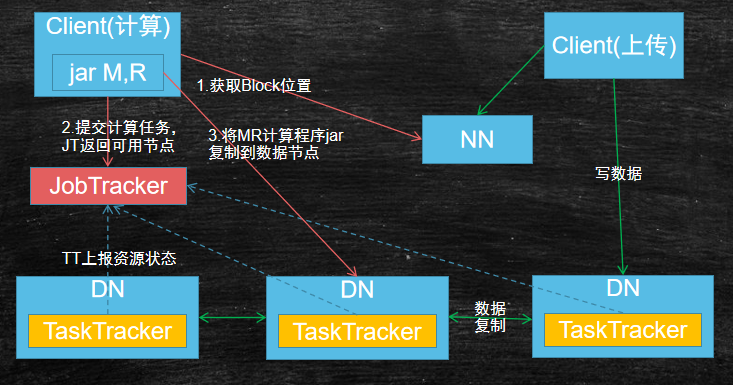
- 客户端
- 需要从NN中获取到源数据保存的DN节点,从而才能将MR计算程序拷贝到相应节点运行(计算向数据移动),实际的计算(执行M/R方法)发送在数据节点
- 而适合运行此计算任务的需要从JobTracker中获知
- 上传源数据的客户端和发起计算任务的客户端可能是不同的客户端
JobTracker(JT)主要负责管理集群资源和任务调度- 接受TaskTracker(TT)上报的资源数据,从而判断出适合运行MR程序的节点
- 将MR计算程序拷贝到相应节点执行计算
- JobTracker以常服务(永久运行的)运行在MR中,YARN之后MR则无此常服务
TaskTracker(TT)主要负责当前DataNode资源上报,每个DataNode会运行一个TaskTracker- 存在问题
- JobTracker单点问题(不稳定、负载不好)
- JobTracker和MR耦合度太高,不利于整合对其他框架
Haddop 2.x
YARN原理
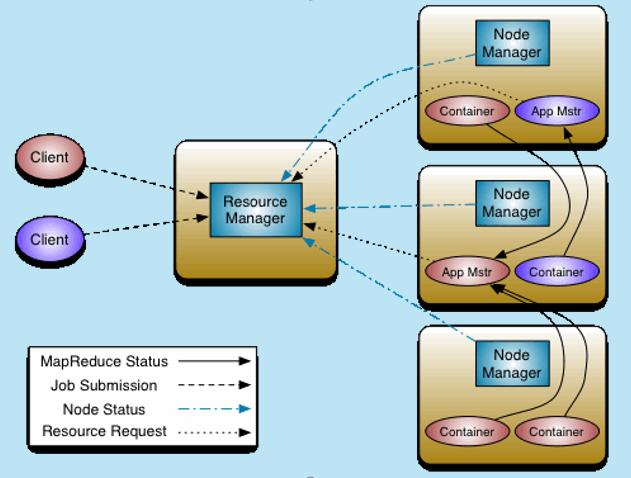
- ResourceManager:类似JobTracker(只包含其资源管理,不包含其任务调度)
- 接受NodeManager上报的状态信息
- 接受客户端发起的计算任务请求
- 客户端会把计算程序(jar)上传到HDFS集群,最终会由AppMaster读取并分发到其他节点,计算完成后会清除此jar
- ResourceManager会告诉NodeManager启动一个AppMaster(即JobTracker的任务调度功能)
- AppMaster会向ResourceManager上报信息(监控挂掉可重新启动一个新的),并提交请求的资源信息(需要的Container数)
- ResourceManager会告诉NodeManager启动Container(用来执行M/R方法),Container向AppMaster上报信息
- 每个请求任务有各自独立的AppMaster,从而减少了负载。计算任务完成,AppMaster和Container会停止
- 集群单点有个节点运行ResourceManager
- 可基于ZK进行HA部署,但是和HDFS不同的是不需要ZKFC这个角色
- Hadoop 1.x的时候HDFS存在单点故障,因此在开发Haddop 2.x的时候增加了HA,但是为了向老版本兼容,不想过多修改1.x的程序,从而出现了ZKFC来控制HA的切换
- 而在Haddop 2.x的时候开发YARN是新的模块,从而切换功能直接在ResourceManager中
- NodeManager:类似TaskTracker,运行在各个DN
Hadoop安装
- 本文基于
hadoop-2.10.1(jdk1.8) - HA模式安装:https://hadoop.apache.org/docs/r2.10.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
- 单节点安装见下文)
HDFS安装
服务器配置
| 服务器名 | ip | NameNode | DataNode | JN | Zookeeper | ZKFC |
|---|---|---|---|---|---|---|
| node01 | 192.168.6.131 | Y | Y | Y | ||
| node02 | 192.168.6.132 | Y | Y | Y | Y | Y |
| node03 | 192.168.6.133 | Y | Y | Y | ||
| node04 | 192.168.6.134 | Y | Y |
date检查4台机器的时间是否相差不大(30秒内),并查看是否关闭防火墙- 4台主机的
/etc/hosts文件都需要包含一下内容
1 | 192.168.6.131 node01 |
免密登录
- 免密登录:使NN(node01和node02)可以免密码登录到自己和其他3台服务器
- 启动start-dfs.sh脚本的机器,会去启动其他节点
- 在HA模式下,每一个NN所在节点会启动ZKFC,ZKFC会用免密的方式控制自己和其他NN节点的NN状态
1 | ## 设置node01 |
在node01上进行安装hadoop
1 | sudo mkdir /opt/bigdata |
vi $HADOOP_HOME/etc/hadoop/core-site.xml进行如下配置。配置项参考
1 | <configuration> |
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml进行如下配置。配置项参考文档
1 | <configuration> |
vi $HADOOP_HOME/etc/hadoop/slaves配置DataNode主机名
1 | node02 |
拷贝项目目录到其他3台机器
1 | # 提前在其他机器创建目录 |
初始化
- 安装并启动Zookeeper。参考/_posts/arch/zookeeper.md。
jps会发现有一个QuorumPeerMain的进程 - 初始化(第一次安装才需要)
- 切换test用户执行(则创建的数据目录所属用户为test)
- 先启动JN
hadoop-daemon.sh start journalnode分别在三台JN节点上执行命令进行启动- 可通过
jps查看相应节点是否有JournalNode进程 - 或查看日志是否有错,如
tail -f /opt/bigdata/hadoop-2.10.1/logs/hadoop-root-journalnode-node02.log不是.out文件 - 启动/重启程序时,都必须先启动JN,因为JN中存在最完整的数据;如果先启动了NN,则可能吧NN中不完整的数据覆盖掉了JN中的数据
hdfs namenode -format初始化NN元数据- 选择一个NN 做格式化,第一次运行格式化hdfs获得元数据(不报错则成功,应该会有类似`Storage directory /var/bigdata/hadoop/dfs/name has been successfully formatted.`的日志) - 只能在一台机器上执行一次,之后也不用执行。因为每次执行会生成一个唯一clusterID,如果两台机器都执行则会产生两个不同的clusterID - 会创建上述`/opt/data/hadoop`文件夹及其name子文件夹(/var/bigdata/hadoop/dfs/name/current) - 并在里面创建`fsimage`文件和VERSION等文件 - 且会将NN的数据同步到JN相应目录,如:/var/bigdata/hadoop/dfs/jn/aezocn/current/VERSIONhadoop-daemon.sh start namenode启动上述格式化的NN节点,以备另外一台同步。jps会出现一个NameNode的进程hdfs namenode -bootstrapStandby在另外一台NN中以Standby模式初始化- 会自动同步元数据,且打印日志如
Storage directory /var/bigdata/hadoop/dfs/name has been successfully formatted. - 或者手动拷贝上述fsimage到另外一台NameNode(node02):
scp -r /var/bigdata/hadoop root@node02:/var/bigdata
- 会自动同步元数据,且打印日志如
hdfs zkfc -formatZK在主NN中运行- 在某一台NameNode上初始化Zookeeper,只需在一台机器上执行一次,之后不用执行
- 本质是在ZK上创建一个hadoop目录(/hadoop-ha/aezocn),之后会创建ZKFC的临时节点
YARN安装
- 在node03-node04上运行ResourceManager;NodeManager运行在各个DN上,无需额外配置
- 安装启动
1 | # 只需要在安装好的hdfs配置上,增加几个配置文件。无需重启hdfs |
- 启动参考YARN启停
- mapred-site.xml
1 | <property> |
- yarn-site.xml
1 | <property> |
启动/停止/使用
HDFS启停
- 需先确保Zookeeper集群已经启动
hadoop-daemon.sh start journalnode用test用户(hadoop所属用户)分别在三台JN(node02-node04)节点上执行命令进行启动(必须在NN之前启动)- 自动启动:可在
/etc/rc.local中增加代码sudo -H -u test bash -c '/opt/bigdata/hadoop-2.10.1/sbin/hadoop-daemon.sh start journalnode'自动启动(centos7需先chmod +x /etc/rc.d/rc.local激活此文件)
- 自动启动:可在
start-dfs.sh在某一台NameNode上用test用户启动start-all.sh包含了 start-dfs.sh 和 start-yarn.sh此时node01会通过免密码登录启动其他机器上的hadoop服务(NN、DN、ZKFC, JN已提前启动)
- journalnode在上述启动过,此处不会重新启动
- 启动后,则会自动同步数据到JN,如:edits_inprogress_0000000000000000001
- 启动后,查看ZK(
zkCli.sh -> ls /hadoop-ha/aezocn)会发现多出ActiveBreadCrumb, ActiveStandbyElectorLock两个节点(ActiveStandbyElectorLock记录了当前谁获得了锁,即那个节点是active) 需要保证数据目录
/var/bigdata/hadoop为test用户有权读写(因为此处通过test用户启动)1
2
3
4
5
6
7
8
9
10
11
12
13
14# 日志如下
Starting namenodes on [node01 node02]
node01: starting namenode, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-namenode-node01.out
node02: starting namenode, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-namenode-node02.out
node02: starting datanode, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-datanode-node02.out
node03: starting datanode, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-datanode-node03.out
node04: starting datanode, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-datanode-node04.out
Starting journal nodes [node02 node03 node04]
node02: journalnode running as process 16792. Stop it first.
node03: journalnode running as process 15892. Stop it first.
node04: journalnode running as process 15820. Stop it first.
Starting ZK Failover Controllers on NN hosts [node01 node02]
node02: starting zkfc, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-zkfc-node02.out
node01: starting zkfc, logging to /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-zkfc-node01.out
hadoop-daemon.sh start namenode在某节点运行,则单独启动一个NameNodehadoop-daemon.sh start datanode在某节点运行,单独启动一个DataNodehadoop-daemon.sh start journalnode在某节点运行,单独启动一个JNhadoop-daemon.sh start zkfc在某节点运行,单独启动一个ZKFC
- 访问
http://node01:50070和http://node02:50070查看NameNode监控。会发现一个为active,一个为standby- 关闭active对应的NameNode服务,可发现standby对应的服务变为active,实现了NameNode接管
- 如node02无法切换为active,可查看对应ZKFC的日志
tail -f /opt/bigdata/hadoop-2.10.1/logs/hadoop-test-zkfc-node02.log。常见无法切换错误- 提示
Unable to fence NameNode,可检查是否可进行免密码登录 - 提示
ssh: bash: fuser: 未找到命令,可在NameNode上安装yum -y install psmisc
- 提示
- 手动切换nn2为active:
hdfs haadmin -transitionToActive nn2(在未开启自动切换模式下才可使用)
- 如node02无法切换为active,可查看对应ZKFC的日志
- 关闭active对应的ZKFC服务,可发现standby对应的服务变为active
- 关闭active对应节点的网络,此时会发现standby对应节点会抢到ZK锁,但是无法将自己升级为active(因为ZKFC无法与原active节点通信,因此无法确定对方节点状态)
- 关闭active对应的NameNode服务,可发现standby对应的服务变为active,实现了NameNode接管
stop-dfs.sh停止所有hadoop服务- 所有的启动日志均在
logs目录,且Hadoop日志文件格式类似:hadoop-用户-角色-节点.log
YARN启停
- 前确保HDFS启动完成
- 启动NM和RM
1 | # (root执行亦可) 在node01上执行,会在所有 DN 上启动 NM(NodeManager)。但是不能自动启动RM,需要手动启动;由于配置了 RM(ResourceManager) 不会在node01上启动,会看到执行此脚本后先在node01上启动RM,之后会自动退出(正常现象) |
HDFS简单使用
1 | ## 查看dfs命令帮助. 客户端都可以执行,一些只要有集群配置,则可执行hdfs命令,还有一些必须要在NN上执行才可 |
HDFS权限
- hdfs是一个文件系统,类似linux有用户概念
- hdfs没有相关命令和接口去创建用户
- 默认情况使用操作系统提供的用户
- 也可扩展 LDAP/kerberos/继承第三方用户认证系统
- 有超级用户的概念
- linux系统中超级用户:root
- hdfs系统中超级用户:namenode进程的启动用户(如test启动,则test为hdfs的超级用户,其他包括root都为普通用户)
- 有权限概念
- hdfs的权限是自己控制的,来自于hdfs的超级用户
- 默认hdfs依赖操作系统上的用户和组
- 用户权限测试
1 | ## 设置目录权限,在node01(NN)上执行 |
API使用
- 基于IDEA开发hadoop的client
- 在windows上创建
HADOOP_USER_NAME=test的环境变量,用于Hadoop获取当前用户;设置JDK版本和Hadoop服务器版本一致 - 创建maven项目,引入客户端依赖
1 | <dependency> |
- 在resources目录放置core-site.xml、hdfs-site.xml配置文件
HDFS测试代码
1 | public class TestHDFS { |
MapReduce测试代码
- 需要安装好HDFS和YARN
- 提交任务方式
- 将my-mr.jar上传到集群中的某一个节点,再执行类似
hadoop jar my-mr.jar input output的命令提交任务到YARN - 嵌入集群方式,在linux/windows上开发程序并直接提交任务到YARN(计算发生在集群)。参考下文案例
- local单机执行(计算发生在本机)
- 在windows的系统中部署hadoop,并设置HADOOP_HOME
- 设置
mapreduce.framework.name=local和mapreduce.app-submission.cross-platform=true - 额外下载相应版本的
hadoop.dll、winutils.exe(参考:https://github.com/cdarlint/winutils),分别放到C:\Windows\System32和%HADOOP_HOME%/bin目录
- 将my-mr.jar上传到集群中的某一个节点,再执行类似
测试hadoop提供的单词统计案例
1 | # 创建wc程序输入数据保存目录 |
- 案例:计算温度最高的前两天(数据源如下)
1 | hdfs dfs -mkdir -p /data/twc/input |
手写MR程序来完成单词统计
- 操作流程
1 | hdfs dfs -mkdir -p /data/twc/input |
- 将
mapred-site.xml和yarn-site.xml复制到项目的resources目录 - 算法程序如下
1 | // TestWordCount.java |
HDFS单节点安装(不常用)
单节点:http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/SingleCluster.html
- 服务器配置
| 服务器名 | ip | 角色 |
|---|---|---|
| node01 | 192.168.6.131 | NameNode |
| node02 | 192.168.6.132 | SecondaryNameNode、DataNode |
| node03 | 192.168.6.133 | DataNode |
| node04 | 192.168.6.134 | DataNode |
- 检查date、修改hosts、免密码登录(参考上述HA安装)
在node01上进行安装hadoop(参考上述HA安装)
vi etc/hadoop/core-site.xml进行如下配置(参考 https://hadoop.apache.org/docs/r2.10.1/hadoop-project-dist/hadoop-common/core-default.xml)1
2
3
4
5
6
7
8
9
10
11
12<configuration>
<!--配置NameNode的主机名和数据传输端口(文件上传下载)-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<!-- 默认保存在/tmp目录,容易丢失 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop</value>
</property>
</configuration>vi /etc/hadoop/hdfs-site.xml进行如下配置1
2
3
4
5
6
7
8
9
10
11<configuration>
<!-- 配置SecondaryNameNode的Http相关端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node02:50091</value>
</property>
</configuration>vi etc/hadoop/slaves配置DataNode主机名1
2
3node02
node03
node04vi etc/hadoop/masters配置SecondaryNameNode主机名(默认无此文件。HA模式下无SecondaryNameNode,因此无效此步骤)1
node02
拷贝项目目录到其他3台机器并配置hadoop环境变量(参考上述HA安装)
- 在
node01(NameNode)上运行hdfs namenode -format在node01(NameNode)上运行start-dfs.sh在node01(NameNode)上执行stop-dfs.sh停止所有hadoop服务
- 访问
http://192.168.6.131:50070查看NameNode监控、http://192.168.6.132:50090查看SecondaryNameNode监控
flume
ETL: kettle
sqoop、datax
埋点:初中高
oozie、azkanman
参考文章
