介绍
- ZooKeeper官网
- ZooKeeper 分布式协调服务(提供分布式锁),是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件
- zookeeper开源客户端curator
基本概念
- Paxos协议
- ZooKeeper特点
- 最终一致性:为客户端展示同一个视图
- 实时性:系统的客户视图保证在特定时间范围内是最新的。zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口
- 顺序性:客户端的更新将按发送顺序应用
- 统一视图:无论客户端连接到哪个服务器,客户端都将看到相同的服务视图(临时节点数据也可见)
- 可靠性:如果消息被一台服务器接受,那么它将被所有的服务器接受(且被持久化)
- 原子性:更新只能成功或者失败,没有中间状态
- 独立性:各个Client之间互不干预
- ZooKeeper工作原理
- 每个Server在内存中存储一份数据(有的会存在磁盘)
- zookeeper启动时,将从实例中选举一个leader(Paxos协议)
- Leader负责处理数据更新等操作
- 一个更新操作成功的标志是当且仅当大多数Server在内存中成功修改数据
- ZooKeeper可能出现可用和不可用两种状态
- 当Leader挂掉后,集群短暂不可用,此时不会接受客户端请求
- 并且会在200ms左右恢复成可用,即重新选出Leader
- 数据模型
- 是一个目录树结构 => 分组管理
- 每个节点可以存放1MB数据 => 统一配置
- 节点分为:持久节点、临时节点(session)、序列节点
- sequential(序列节点) => 统一命名
- ephemeral(读音:/ɪˈfemərəl/,临时节点) => 分布式锁
ZooKeeper安装和使用
- 基于v3.4.6,使用3台机器进行搭建。文档http://zookeeper.apache.org/doc/r3.4.6/index.html
1 | ## 需要保证安装了JDK,参考[CentOS服务器使用说明.md#安装jdk](/_posts/linux/CentOS服务器使用说明.md#安装jdk) |
- conf/zoo.cfg配置示例
1 | ## 先清空整个文件 |
- 启动与停止
1 | zkServer.sh start # zkServer.sh start-foreground 此方式日志直接打印在前台 |
- 客户端使用
1 | zkCli.sh # 进入zookeeper客户端命令行,如:[zk: localhost:2181(CONNECTED) 0] |
- 客户端命令
1 | # help展示帮助 |
原理
- 角色:Leader、Follower、Observer
- 只有Follower才能选举投票(加快恢复速度)
- 只有Leader、Follower可进行事务请求Proposal的投票
- Observer:是弱化版的Follower(不能进行任何投票)
- 引入这个角色主要是为了在不影响集群事务处理能力的前提下提升集群的非事务处理的吞吐量
- 利用Observer放大查询能力,读写分离。zk适合读多写少的场景
zookeeper每个节点需配置几个端口。可通过
netstat -natp | egrep '(2181|2888|3888)'查看- 2181:客户端连接使用
- 2888:leader接受write请求,即其他从节点会连接到leader的2888端口
- 3888:选主投票用的
启动后3888端口的连接如下,假设4个节点,则每个节点和其他3个节点进行连接
客户端watch一个目录后,当该目录发生改变后,会触发事件通知到客户端
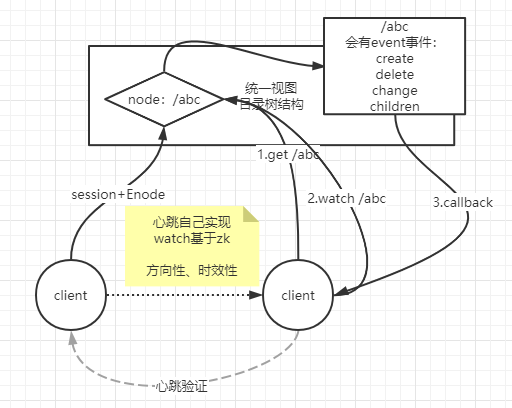
- zookeeper是有session的概念,因此客户端使用时不能使用线程池
Zab协议
- ZooKeeper 是通过
Zab(ZooKeeper Atomic Broadcast,ZooKeeper 原子广播协议)协议来保证分布式事务的最终一致性和支持崩溃恢复 ^1- ZAB基于Paxos算法演进而来。Paxos 是理论,Zab 是实践
- Zab 协议主要功能:消息广播、崩溃恢复、数据同步
消息广播。写操作可理解为2PC过程
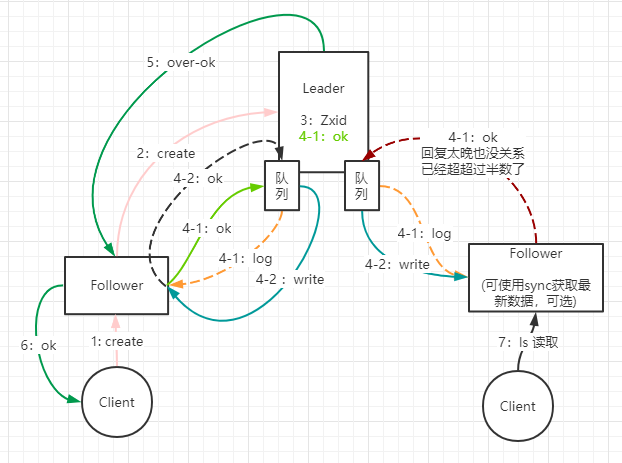
- 接受写请求:在 ZooKeeper 中所有的事务请求都由 Leader 节点来处理,其他服务器为 Follower
- Leader或Follower都对外提供读写操作
- 客户端对Follower发起写操作时,会由Follower提交到Leader进行写操作
- 广播事务操作:Leader 将客户端的事务请求转换为事务 Proposal(提议),并且将 Proposal 分发给集群中其他所有的 Follower
- Leader会为每个请求生成一个Zxid(高32位是epoch,用来标识leader选举周期;低32位用于递增计数。在Paxos中epoch叫Ballot Number)
- Leader 会为每一个 Follower 服务器分配一个单独的 FIFO 队列,然后把 Proposal 放到队列中
- Follower 节点收到对应的 Proposal 之后会把它持久到磁盘上(zk的数据状态在内存,用磁盘保存日志)。当完全写入之后,发一个 ACK 给 Leader
- 广播提交操作:Leader 等待 Follwer 反馈,当有过半数的 Follower 反馈信息后,Leader 将再次向集群内 Follower 广播 Commit 信息(上述Proposal),Follower 收到 Commit 之后,完成各自的事务提交
- 接受写请求:在 ZooKeeper 中所有的事务请求都由 Leader 节点来处理,其他服务器为 Follower
- 崩溃恢复。若某一时刻 Leader 挂了,此时便开始 Leader 选举,过程如
- 当A节点发现Leader挂掉后,将本节点状态变更为 Looking(选举状态)
- 然后A节点会发出一个投票,参与选举
- 发起投票者都会投一票给自己
- 其他节点收到投票提议,开始处理投票选举
- 如果B节点收到A节点的投票提议,当A发现B的zxid-myid比自己小时,会反驳提议(即A也发起自己的投票提议)
- 新Leader选举原则
- 先考虑Zxid大的,再考虑myid大的。如初始化集群启动时Zxid=0,因此看myid;和启动顺序有关,如果过半,则已启动的中的myid最大的为Leader
- 如果收到超过半数的票则会当选为Leader。即3个节点得2票、4个节点得3票,只要有超过半数的节点存活,则ZK服务仍然可用
- 数据同步
- 崩溃恢复完成选举以后,接下来的工作就是数据同步,在选举过程中,通过投票已经确认 Leader 服务器是最大Zxid 的节点,同步阶段就是利用 Leader 前一阶段获得的最新Proposal历史,同步集群中所有的副本
一致性
- CAP理论
- C一致性。一致性分类:https://blog.csdn.net/nawenqiang/article/details/85236952
- A可用性
- P分区容错性
- 用作注册中心时,Eureka、Zookeeper、Nacos的CAP区别
- Eureka实现了AP,保证了可用性,实现最终一致性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务
- Zookeeper实现了CP,在选举leader时,会停止服务,直到选举成功之后才会再次对外提供服务,这个时候就说明了服务不可用。C中的写入强一致性,丧失的是C中的读取一致性
- Nacos既支持既支持AP,也支持CP
Java中使用
- pom中导入客户端依赖(客户端需要和服务端保持同一版本)
1 | <!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper --> |
简单示例
测试代码
1 | /** |
实现分布式配置中心/服务发现
- 使用zk的
watch功能 - 参考:https://github.com/oldinaction/smjava/tree/master/zookeeper/src/main/java/cn/aezo/zookeeper/distributed_config_center_service_discover
实现分布式锁
- 参考分布式架构原理及选型方案.md#分布式锁
- 使用zk的session功能可防止死锁
- 使用zk的sequence+watch
- 使用zk的
watch功能可在释放锁时,其他节点更快得知(如果主动轮询判断是否可获取锁则会有延时) - 使用sequence可让后一个节点关注前一个节点的变化。永远让第一个节点获得锁,当第一个节点执行完毕后释放锁,从而触发后面一个节点的事件回调进行锁获取
- 释放锁只会给后一个节点发送回调通知,如果释放锁给全部节点发送回调,一个弊端是zk需要对多个节点发送数据,另外一个弊端是其他节点获取通知后可能产生锁争抢
- 使用zk的
- 参考:https://github.com/oldinaction/smjava/tree/master/zookeeper/src/main/java/cn/aezo/zookeeper/distributed_lock
参考文章
