简介
安装
pip install scrapy安装(v1.5.0)
linux安装(python3)
- 确保安装了
python3 pip install scrapy- 报错
requirement Twisted>=13.1.0,通过pip install Twisted又无安装源,因此通过源码安装wget https://twistedmatrix.com/Releases/Twisted/17.1/Twisted-17.1.0.tar.bz2tar -jxvf Twisted-17.1.0.tar.bz2解压时报错tar (child): bzip2: Cannot exec: No such file or directory,此时需要先安装bzip2yum -y install bzip2- 解压完成后进入到Twisted-17.1.0源码目录
python setup.py install完成后上述源码可删除
- 安装成功
Twisted后再安装scrapy
原理
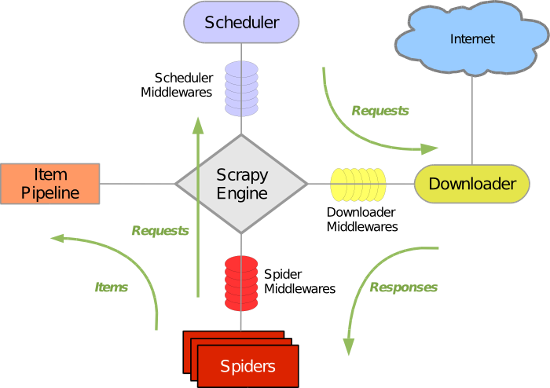
- 引擎(
Scrapy Engine),用来处理整个系统的数据流,触发事务。 - 调度器(
Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。 - 下载器(
Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。 - 蜘蛛(
Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 - 项目管道(
Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(
Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。- 当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等)
- 在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
- 蜘蛛中间件(
Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(
Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
代码结构
scrapy startproject testScrapy创建testScrapy项目文件结构
1
2
3
4
5
6
7
8
9
10testScrapy/
scrapy.cfg
testScrapy/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...- scrapy.cfg: 项目的配置文件
- testScrapy/: 该项目的python模块。之后您将在此加入代码。
- testScrapy/items.py: 项目中的item文件.
- testScrapy/pipelines.py: 项目中的pipelines文件.
- testScrapy/settings.py: 项目的设置文件.
testScrapy/spiders/: 放置spider代码的目录.
一个包是一个带有特殊文件
__init__.py的目录。__init__.py文件定义了包的属性和方法。其实它可以什么也不定义;可以只是一个空文件,但是必须存在。如果__init__.py不存在,这个目录就仅仅是一个目录,而不是一个包,它就不能被导入或者包含其它的模块和嵌套包
运行
scrapy crawl hscode运行(必须进入到项目目录)- 脱离项目执行
- 参考run.py. 运行
python /home/testScrapy/run.py - shell脚本运行, 参考start_hscode.sh. 可以脱机运行
- 参考run.py. 运行
- 执行过程
- hscode_spider.py
- Scrapy为Spider的 start_urls 属性(或者从重写的start_requests开始执行)中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request
- Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法进行解析
- 基于Item(类似实体),提取response中的数据(Scrapy使用了一种基于 XPath 和 CSS 表达式机制)
- pipelines.py
- 进行数据清洗、验证和存储
- hscode_spider.py
常见问题
- scrapy爬虫出现
Forbidden by robots.txt- 关闭scrapy自带的ROBOTSTXT_OBEY功能,在setting找到这个变量,设置为False即可解决
向scrapy中的spider传递参数:
scrapy crawl myspider -a myName=smalle1
2
3
4
5
6class MySpider(scrapy.Spider):
name = 'myspider'
def __init__(self, myName=None, *args, **kwargs):
super(MySpider, self).__init__(*args, **kwargs)
self.start_urls = ['http://www.aezo.cn/name/%s' % myName]
