Redis简介
- redis.cn、官网:http://redis.io/、Redis Github、redis 在线测试
- Redis
- 是一款开源的,基于 BSD 许可的,高级键值 (key-value) 缓存 (cache) 和存储 (store) 系统
- 由于 Redis 的键包括
string,hash,list,set,sorted set,bitmap和hyperloglog,所以常常被称为数据结构服务器 - 单实例,单进程、单线程(epoll),占用资源少(单实例只使用1M内存)
- 版本3.×(最早版本)为单线程
- 版本4.×,负责处理客户端请求的线程单线程,但是开始加了点多线程的东西(异步删除)
- 版本6.x 开始,全面支持多线程。将网络数据读写、请求协议解析通过多个IO线程来处理,真正执行命令的线程仍然是主线程单独进行操作
- 常见的缓存memcached、redis比较参考
- redis windows客户端(64x,官网不提供window安装包):https://github.com/MSOpenTech/redis
- redis客户端连接管理软件
- Navicat Premium 17支持redis
- (推荐)AnotherRedisDesktopManager
- RedisDesktopManager
- java操作redis(客户端jar)
- bio-nio-select-epoll,参考网络IO
安装Redis服务
- Windows
- 方式一: 下载Redis-7.4.2-Windows-x64-cygwin-with-Service.zip
- 执行
install_redis_service.bat安装到服务;默认没有设置密码,可修改redis.conf设置requirepass参数
- 执行
- 方式二: 下载redis windows客户端(3.2.100):https://github.com/MSOpenTech/redis
- 直接启动解压目录下的:
redis-server.exe服务程序;redis-cli.exe客户端程序,即可在客户端使用命令行进行新增和查看数据(默认没有设置密码)
- 直接启动解压目录下的:
- 设置密码
- 修改
redis.windows.conf,将# requirepass foobared改成requirepass your_password(行前不能有空格) - cmd进入到redis解压目录,运行
redis-server redis.windows.conf,之后登录则需要密码
- 修改
- 方式一: 下载Redis-7.4.2-Windows-x64-cygwin-with-Service.zip
- Linux
1 | ## 简单的可直接安装 |
- Mac
- 安装
brew install redis - 启动
brew services start redis - 配置文件路径如
/opt/homebrew/etc/redis.conf
- 安装
- 解决服务器Redis无法连接问题(内网):https://blog.csdn.net/qq_57408330/article/details/129681386
配置文件
1 | # 如果设置为yes,那么只允许我们在本机的回环连接,其他机器无法连接 |
命令使用
- string
- 字符类型
- 数值类型计算
- bitmap位图
- list
- 栈(同向操作)
- 队列(反向操作)
- 数组
- 阻塞,单播队列(FIFO)
- hash
- set
- 无序去重集合
- 随机事件,如可用于抽奖
- sorted set
基础
1 | redis-cli # 启动客户端 |
字符串(string)
1 | set name smalle |
- setbit二进制图
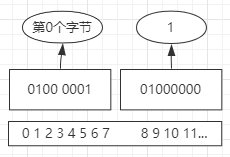
list
- 首字母L/R代表left/right,L有时候可能指list,B代表blocking
- list结构
1 | help @list |
hash(map)
- 命令字母H开头表示hash
1 | help @hash |
set
1 | help @set |
sorted_set
- Z开头命令表示sorted set,REV表示取反(reversal)
- 排序器实现原理:skip list(跳跃表))
1 | help @sorted_set |
进阶
使用场景
incr可用于统计不要求太精准的字段,如点赞数、评论数、抢购、秒杀等。从而规避并发下对数据库的事物操作,完全由redis内存操作代替set my_lock id_12345678 nx ex 60实现分布式锁(nx不存在才能创建进行加锁,ex过期时间是60s防止死锁),参考下文实现分布式锁。其中nx表示如果不存在此key时才允许创建msetnx命令:nx如上,m表示set多个key,此时要么都成功要么都失败。可用于字符串类型的原子性赋值操作setbit位图命令使用。参考上文setbit相关案例1
2
3
4
5
6
7
8
9
10
11
12
13## 记录每个用户一年365天是否登录过 => 46字节*1000w ~= 460M => 相比存储空间小且速度快
setbit smalle 0 1
setbit smalle 7 1
setbit smalle 364 1
strlen smalle # 46,只需46个字节即可保存一个人一年的登录状态
bitcount smalle -7 -1 # 1,获取用户最近一周的登录次数;bitcount统计smalle中-7到-1字节(最后7个字节)出现1的次数
## 统计一段时间的活跃用户数。假设A用户使用第1号位,B用户使用第7号位,且A用户在1-1(0101)、1-2(0102)号登录了,B用户只在1-2登录
setbit 0101 1 1
setbit 0102 1 1
setbit 0102 7 1
bitop or destkey 0101 0102 # 按位或操作,并将结果赋值给destkey
bitcount destkey 0 -1 # 2 => 这两天的活跃用户数为2
发布订阅
1 | # 客户端A往p1通道里面发送消息 |
pipeline管道
- 在管道中可一次性发送多条命令
1 | # nc连接服务器,然后直接发数据回车即可获得返回 |
transactions事物
- 注意redis是单线程的,因此是按照时间先后顺序响应客户端命令
1 | ## 相关命令 |
数据有效期(作为缓存)
- redis作为缓存数据不重要、不是全量数据,缓存应该随着访问变化(保存热数据,内存是有限的)
key的有效期
- 通常Redis keys创建时没有设置相关过期时间,他们会一直存在,除非使用显示的命令移除,例如使用DEL命令
expire倒计时,当key执行过期操作时,Redis会确保按照规定时间删除他们(尽管中途使用过,过期时间也不会自动改变)。从 Redis 2.6 起,过期时间误差缩小到0-1毫秒expireat设定再某个时间点失效pexpire基于正则的倒计时pexpireat- 过期判定原理:被动访问判定、主动轮询判定
- 被动访问判定:当访问某个key时判断其是否过期,过期则先执行移除
- 主动轮询判定为增量
- 默认每秒进行10次扫描,每次随机取20个key判断,超过25%过期,则再取20个判断,并且默认的每次扫描时间上限不会超过25ms
- 目的:redis是单线程,此时稍微牺牲下内存(延时过期),但是保住了redis性能为王
1 | ## expire和expireat |
回收策略配置/数据淘汰机制
- 回收策略不同于上文过期策略,二者有一定的区别
- 将redis当做使用LRU算法的缓存来使用
1 | # 编辑支持的最大内存(maxmemory)和回收策略 |
持久化(数据库)
- redis持久化主要有:RDB、AOF、AOF&RDB(默认)
- redis作为数据库,数据不能丢失,即需要做持久化,一般使用AOF(最好结合RDB);如果作为缓存使用RDB就行,数据丢失可再从数据库获取
RDB方式持久化
- 调用bgsave命令时,使用
fork()进程时的copy-on-write写时复制机制来实现。具体参考Copy-On-Write写时复制 - RDB特点
- 优点:恢复速度相对快
- 不支持拉链,只有一个dump.rdb文件(为二进制编码,但是以REDIS开头)
- 丢失数据相对多一些,两次持久化之间的数据容易丢失
- rdb配置
1 | ################################ SNAPSHOTTING ################################ |
- 执行备份导出及导入
1 | ## 连接待导出的redis成功后. 查看目录,如: /var/lib/redis |
AOF方式持久化
AOF(Append Only Mode) Redis的写操作记录到文件中。默认是关闭的,可通过配置文件appendonly yes开启- 特点
- 丢失数据少
- 弊端:体量大、恢复慢。减少日志量的方法如下可通过重写实现
- AOF重写
- 手动重写命令rewriteaof和bgrewriteaof
- aof自动重写条件参考下文配置文件
- 重写时先fork一个子进程并创建aof临时文件,然后将数据库中的数据通过命令保存到aof临时文件(如果开启了AOF&RDB混合使用,则将数据通过RDB的方式保存到AOF临时文件中),最后用临时文件覆盖掉原AOF文件
- 推荐使用AOF&RDB混合使用
- redis当做内存数据库,写操作会触发IO,相关配置如
1 | ############################## APPEND ONLY MODE ############################### |
- aof文件说明
1 | # 表示是RDB和AOF混合使用 |
集群方式
- redis单机(单节点、单实例)问题
- 单点故障
- 容量有限
- 压力太大
- AKF拆分原则
- X轴:表示主备,全量备份
- Y轴:基于业务模块进行细分,可再结合X周特性进行主备
- Z轴:在XY的情况下,对某模块下的单一业务再次划分XY(如对用户基于身份证号进行划分)
- 设计微服务的4个原则:AKF拆分原则、前后端分离原则、无状态服务、Restful的通信风格
- 数据同步方式
- 同步(强一致性):client对主请求,主保存数据后通知给备,等所有备返回后再返回给client。可能丢失可用性
- 异步(弱一致性):client对主请求,主保存数据后立即返回给client。之后再同步给备。可能产生数据不一致
- 队列(最终一致性):client对主请求,主保存数据后并发送给队列(如kafka),然后返回给client。之后从节点从队列中获取数据并保存
- 主备和主从(redis的这两种模式可进行配置,默认主备)
- 主备:一般只有主对外提供服务(无特殊说明,有时候提到的主从也是主备的意思)
- 主从:主提供全量服务,从提供部分服务
- 这两种情况都需要有一个主,如果主挂了则也不可用,因此需要对主做高可用(HA)
- 高可用(HA)方式
- 一般使用奇数节点监控,并超过半数进行主备切换
- 为什么使用奇数节点进行监控:如3台和4台都允许挂1台,同样的情况使用4台更容易挂掉一台
- 一般使用奇数节点监控,并超过半数进行主备切换
- 集群相关配置
1 | # 当一个slave失去和master的连接,或者同步正在进行中,slave的行为有两种可能: |
Redis Cluster
- Redis官方集群方案
redis预分区
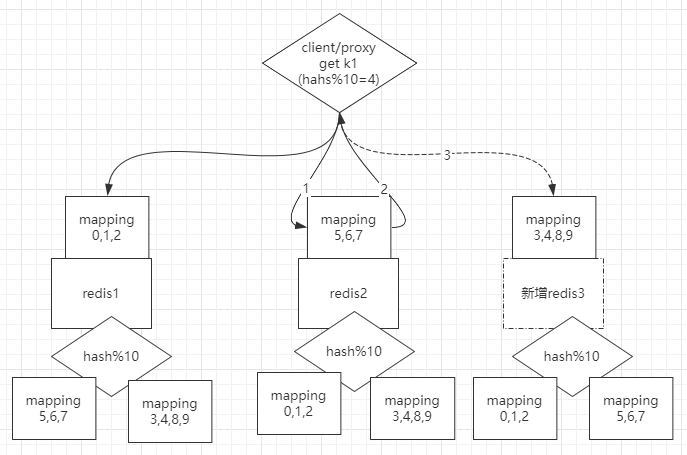
- 假设刚开始只有2个节点,一般此时算法是hash%2,此时可改成直接hash%10(实际会更大,Redis 集群有16384个哈希槽),那么所有数据会在刚开始就分布在不同的槽位(0-9);当新增节点时,只需要将部分槽位的数据复制到新节点即可;当客户端查询的数据不在该节点时,会自动路由到目标节点
- Redis Cluster特点
- 多主(高可用)多从(主备模式),去中心化,支持分区:从节点作为备用,复制主节点,不做读写操作,不提供服务
- 支持动态扩容节点
- 节点之间相互通信,相互选举,不再依赖sentinel
- 相比较sentinel模式,多个master节点保证主要业务(比如master节点主要负责写)稳定性,不需要搭建多个sentinel实例监控一个master节点
- Sentinel模式主要针对高可用(HA),而Cluster模式是不仅针对大数据量,高并发,同时也支持HA
- 直连某个redis,会自动进行跳转(下文的代理则是连接代理端口)
- 部分情况下,支持事物(多条命令执行期间,没有进行redis端口跳转的情况下才支持)
- 支持hash tag
- Redis Cluster测试
1 | # Redis Cluster 在5.0之后取消了ruby脚本 redis-trib.rb的支持。而是集成在redis-cli进行集群管理,查看Redis Cluster帮助 |
基于docker搭建集群
- (3主3从)参考:https://juejin.cn/post/7095675331696132127
- 需要提前创建网络如
docker network create sq-redis
- 需要提前创建网络如
主备设置实践(replicaof)
- 推荐使用Redis Cluster(参考下文)
- 主备设置相关命令
1 | # 在备节点(6380)中运行,追随主节点(6379)。5.0之前的命令使用slaveof |
主备配置完整测试(伪主备)
1 | # 1.在一台机器上安装2个redis服务(伪主备),先关闭所有redis服务,之后手动启动 |
高可用(基于Sentinel哨兵)
- 说明
- 主挂了,自动选择出一个新的主节点,Sentinel模式主要针对高可用(HA)
- 更推荐使用Redis Cluster(参考下文)
- Sentinel实践
1 | # 默认`redis-sentinel`程序在redis安装源码的src目录,安装到特定目录时只是将`redis-sentinel`程序链接到`redis-server`(即只能通过redis-server启动) |
分区/片
- 一般针对业务无法拆分的功能,受到单机容量限制,从而需要进行分区/片(每个节点存放的不是全量数据)
分区方式(以下3个模式均不能做数据库用)
- 基于
modula算法(hash取模)拆分- 缺点:取模的数必须固定,影响分布式下的扩展性(增加节点必须全量重新hash计算)
- 基于
random算法拆分(随机放到不同的节点)- 缺点:客户端不能精确知道数据具体存放的节点
- 应用场景:消息队列
- 客户端通过lpush存放到某个key的集合中,另外一个客户端只需要通过rpop任意取出一个进行消费即可
- 类似kafka,此时key可理解为topic,redis节点可认为是partition
- 基于
ketama算法(一致性hash算法)拆分- 一致性hash算法 ^5
- 是对2^32方取模,即一致性Hash算法将整个Hash空间组织成一个虚拟的圆环,Hash函数的值空间为0 ~ 2^32 - 1(一个32位无符号整型)
- 规划一个虚拟哈希环,不同的节点通过hash算法落到此环的某个点,数据通过key进行hash得到该环的位置,并将数据存放在最近的节点上
- 优点:新增节点可以分担其他节点的压力,不会造成全局洗牌
- 缺点:新增节点造成一小部分数据不能命中(如增加node3,key为xxx对应数据原本在node1,此时客户端会到最近的node3上去找)
- 问题:击穿,压到mysql
- 方案:去取最近的2个物理节点获取数据(只能减少一部分问题)
- 数据倾斜问题:节点太少可能在某一节点的数据太多,可创建多个虚拟节点
- 一致性hash算法 ^5
图解
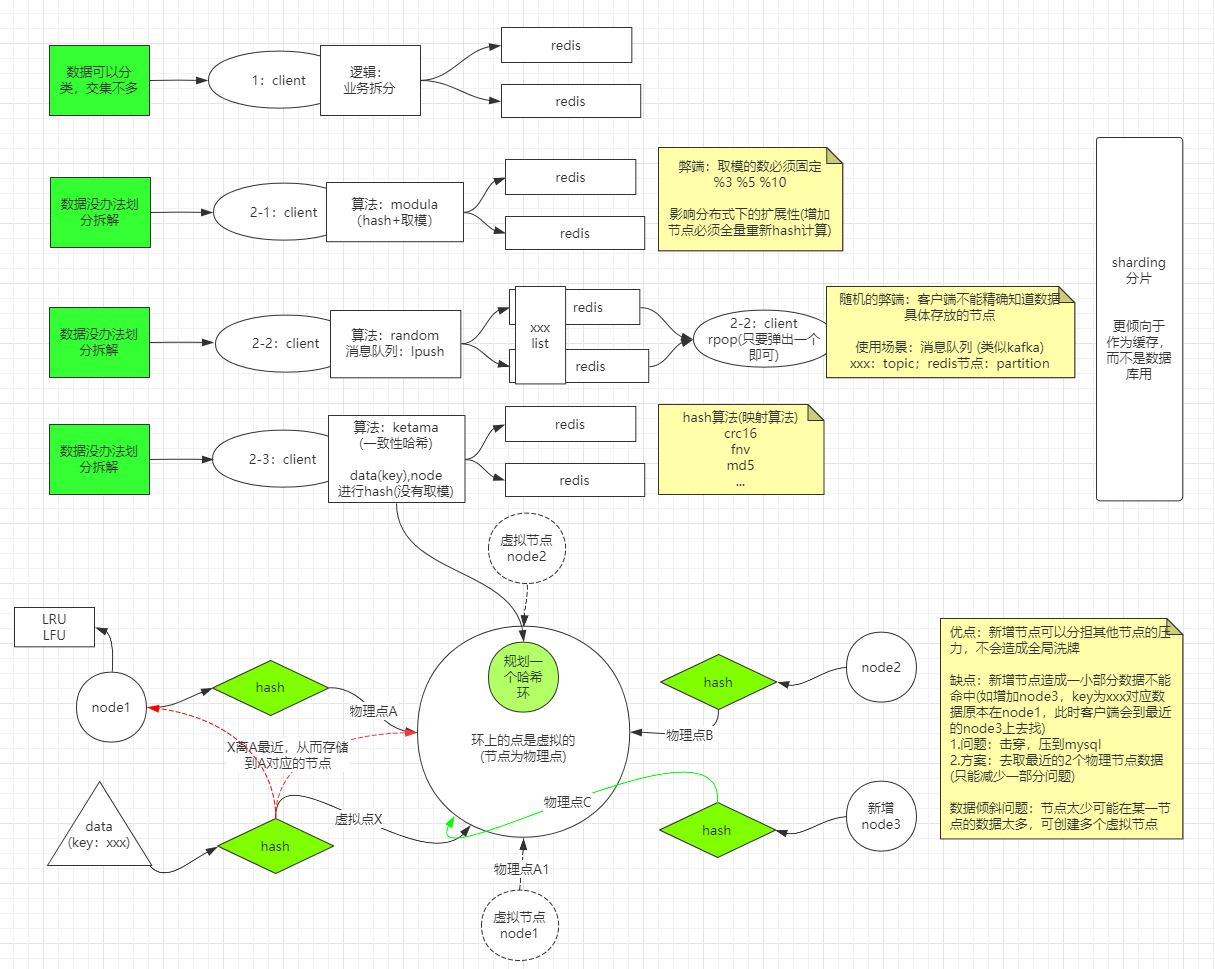
- 缺点
- 以上3个模式均不能做数据库用,主要是新增节点时会出现一段时间的数据丢失
- 解决方案:预分区、Redis Cluster
- 基于
- 数据分治(分区)产生问题
- 聚合操作很难实现(不同的key分布在不同的节点),因此涉及多个key的操作通常不会被支持
- 事务很难实现
- 分区时动态扩容或缩容可能非常复杂
- hash tag
- 命令可以为
{tag1}key1、{tag1}key2,从而可将相同的tag放到同一个节点,实现一定程度的支持事物等功能
- 命令可以为
代理
- 更推荐使用Redis Cluster(参考下文)。直连某个redis,会自动进行跳转,无需代理
如果客户端直接连接redis各节点会产生较高的连接成本,因此可使用代理(类似nginx),客户端只连接代理
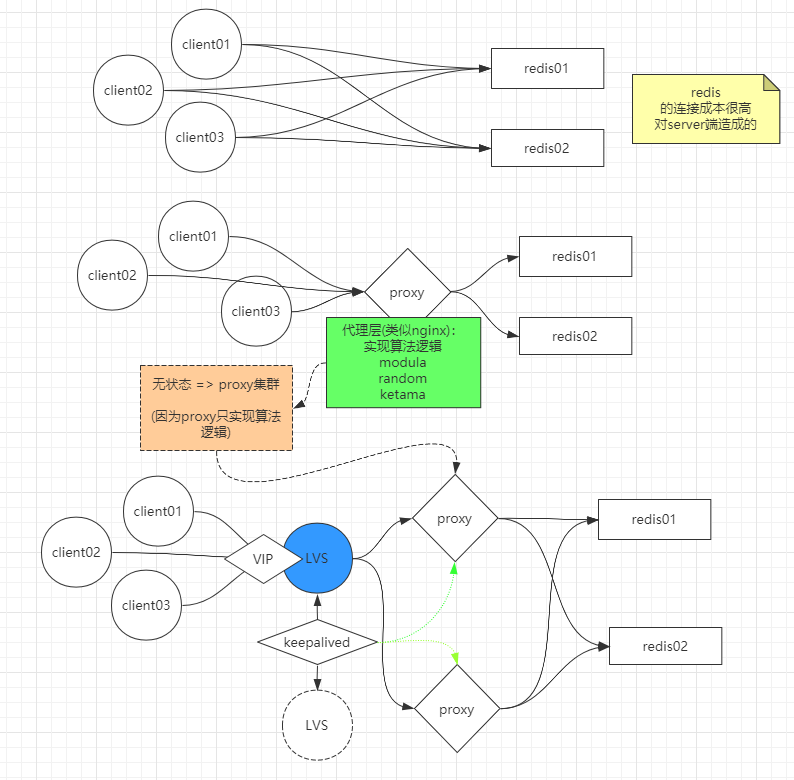
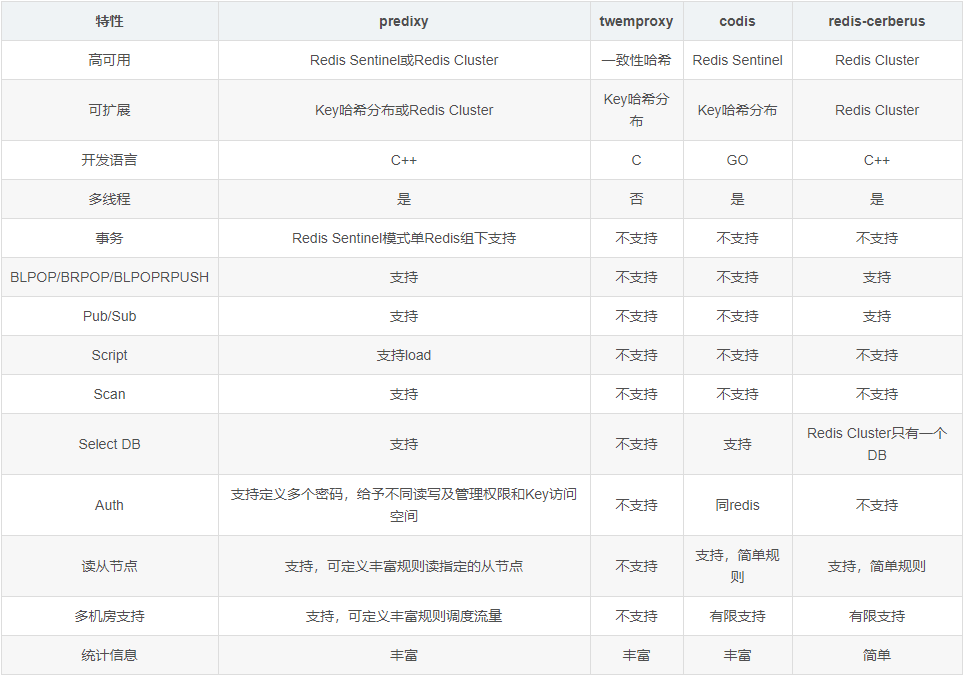
- 常见redis代理组件
redis代理组件对比:https://blog.csdn.net/rebaic/article/details/76384028
twemproxy测试
1 | ## 安装 |
- /etc/nutcracker/nutcracker.yml测试配置
1 | # 代理名称 |
predixy测试
1 | # https://github.com/joyieldInc/predixy/blob/master/README_CN.md |
- 测试配置
1 | ## conf/sentinel.conf |
击穿/穿透/雪崩
击穿、穿透、雪崩
- 击穿
- 某个(热点)key突然失效,造成大量请求同时访问数据库
- 解决方案:setnx加锁取数据到redis,并设置加锁超时时间(防止死锁)
- 穿透
- 访问了大量不存在的(redis中没有)数据
- 解决方案:使用布隆过滤器、布谷鸟过滤器
雪崩
- 大量key同时失效,造成同时大量访问数据库
- 解决方案:缓存预热、随机过期时间、二级缓存、加锁或队列
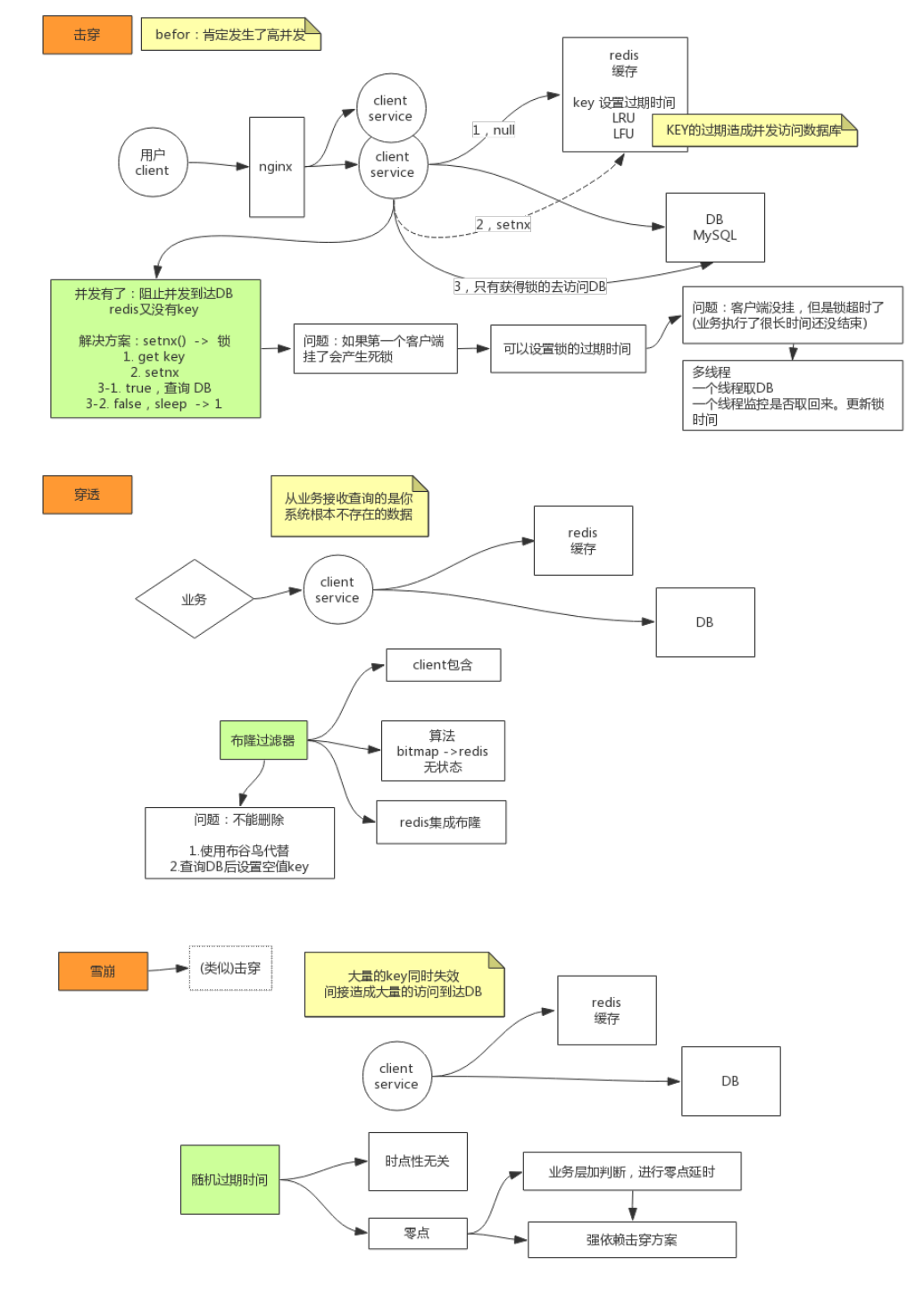
- 击穿
击穿解决方案:setnx加锁,伪代码如下
1 | public String get(key) { |
- 穿透解决方案:布隆过滤器、布谷鸟过滤器
- 雪崩解决方案:随机过期时间、二级缓存、加锁或队列(针对时点性高的场景)
布隆和布谷鸟过滤器
布隆过滤器(Bloom Filter):一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在- 布隆过滤器相对于Set、Map 等数据结构来说,它可以更高效地插入和查询,并且占用空间更少。缺点是判断某种东西是否存在时,可能会被误判,但是只要参数设置的合理,它的精确度也可以控制的相对精确,只会有小小的误判概率
牺牲存储空间来换查询速度
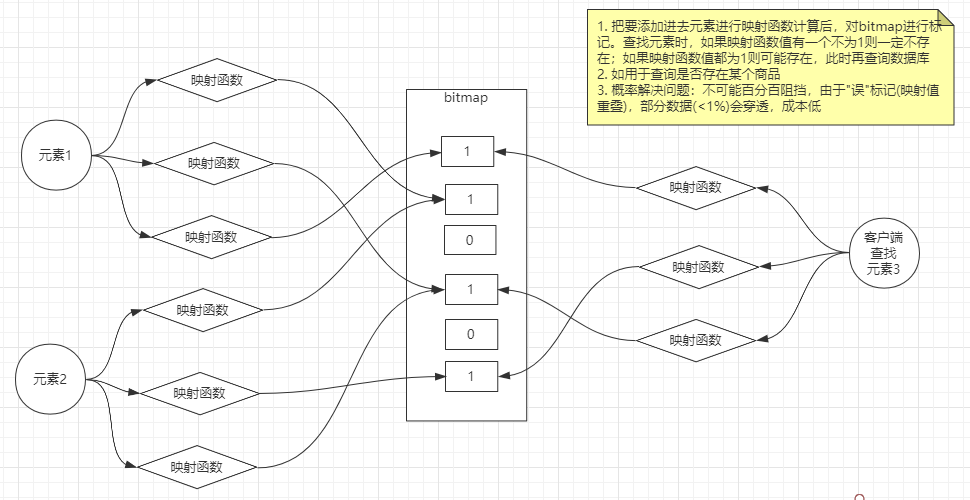
布谷鸟过滤器- 相比布谷鸟过滤器而言布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数
- 解决缓存穿透的问题
- 一般情况下,先查询缓存是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。缓存穿透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库
- 可以使用布隆过滤器解决缓存穿透的问题,把已存在数据的key存在布隆过滤器中。当有新的请求时,先到布隆过滤器中查询是否存在,如果缓存中不存在该条数据直接返回;如果缓存中存在该条数据再查询数据库
- redis中可以手动添加布隆过滤器模块(包含布谷鸟),实际也可在客户端实现布隆算法从而到达过滤效果
1 | ## 安装 |
双写一致性问题
- 当更新数据时,数据库和缓存的更新如何保证数据一致
- 从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案
- 如果不考虑设置过期时间,存在一下几种方式 ^6
- 先更新缓存,再更新数据库:不推荐,明显很容易出现数据不一致的问题
- 先更新数据库,再更新缓存:不推荐,A/B线程先后更新了数据库,B/A先后更新了缓存,导致最终数据不一致
- 先删除缓存,再更新数据库:不推荐,如删除缓存后,在数据库更新完成前,另外一个线程重新读取数据把旧数据写入到缓存
- 可采用延时双删策略,即先删缓存 - 更新数据库 - 延迟一定时间(确保数据读取完成/分库分别同步完成)再删除缓存
- 由于需要延迟会导致吞吐量下降,可使用异步显示进行删除(但是会存在第二次删除失败的情况)
- 先更新数据库,再删除缓存
- 可能出现数据不一致的概率较小(缓存失效线程A查询到一个旧值,线程B更新了数据库并完成了缓存删除,线程A把读取的旧值写入到缓存。出现概率小的原因是读一般是比写快,上述情况是在完成一个写的情况下,读还没完成导致)
- 也可进行解决:进行异步延迟删除,如果更新失败则通过消息队列重试更新。(为了减少对业务代码的入侵,可更新数据库后,订阅binlog日志,进行缓存更新,再结合消息队列处理失败的更新)
Java使用
SpringBoot使用Redis
引入依赖
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>配置
1
2
3
4
5
6
7# Redis缓存配置
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
password:使用
1
2
3
4
5
6
7
8
9
10
private RedisTemplate<String, String> redisTemplate;
// 存储String
redisTemplate.opsForValue().set("myRedisKey", "hello world");
redisTemplate.opsForValue().get("myRedisKey");
// 存储Map
redisTemplate.opsForHash().put("myRedisKey", "myMapKey", "hello world");
redisTemplate.opsForHash().get("myRedisKey", "myMapKey");
Jedis使用
- Jedis为java中操作redis的客户端
- 引入jar包(参考上文pom)
- 使用Java操作Redis需要jedis-3.0.1.jar
- 如果需要使用Redis连接池的话,还需commons-pool2-2.6.2.jar
- 简单使用
1 | // 获取连接,如果使用空参构造,默认值 localhost:6379 端口 |
- 使用连接池连接redis集群(jedis v3)
1 | // 参考: https://blog.51cto.com/u_14402/9184932 |
- 使用连接池连接redis单机(jedis v3)
1 | public class JedisUtil { |
解决session一致性(session共享)
实现分布式锁
1 | public class RedisTool { |
jedis.set(String key, String value, String nxxx, String expx, int time)对应如set my_lock id_12345678 nx ex 60- 使用key来当锁,因为key是唯一的
- value传的是requestId,就可知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。解铃还须系铃人。requestId可以使用UUID.randomUUID().toString()方法生成
- NX,意思是SET IF NOT EXIST,即当key不存在时,进行set操作;若key已经存在,则不做任何操作。互斥性
- PX,意思是要给这个key加一个过期的设置,具体时间由第五个参数决定。防止死锁
- time,与第四个参数相呼应,代表key的过期时间
- 此时只考虑Redis单机部署的场景,所以没有考虑容错性,可使用Redisson
- 分布式锁错误使用
- 错误方式:jedis.setnx()和jedis.expire()组合使用
- 由于这是两条Redis命令,不具有原子性,如果程序在执行完setnx()之后突然崩溃,导致锁没有设置过期时间,那么将会发生死锁
- 网上之所以有人这样实现,是因为低版本的jedis并不支持多参数的set()方法
- 错误方式:jedis.del()方法删除锁
- 这种不先判断锁的拥有者而直接解锁的方式,会导致任何客户端都可以随时进行解锁,即使这把锁不是它的
- 错误方式:jedis.setnx()和jedis.expire()组合使用
redis对模糊查询的缺陷及解决方案
redis本身适合作为缓存工具,不建议使用模糊查询等操作
- 使用https://code.google.com/archive/p/redis-search4j/ ,使用了分词,解决了中文的模糊查询。(效果不好,测试发现会在服务器中存储大量无用的key)
高级
Redis通信协议规范
- Redis通信协议
- Redis客户端使用RESP协议(Redis的序列化协议)与Redis的服务器端进行通信
- 客户端连接到Redis的服务器,创建到端口6379的TCP连接
- 请求-响应模型
- RESP协议描述(RESP protocol description)
- 支持以下数据类型的序列化协议:简单字符串(Simple Strings,响应的第一个字节为
+),整数(Integers,:),数组(Arrays,*),块字符串/批量字符串(Bulk Strings,$)和错误(Errors,-) - 请求-响应流程
- 客户端将命令作为批量字符串的RESP数组发送到Redis服务器
- 服务器(Server)根据命令执行的情况返回一个具体的RESP类型作为回复,有些的数据类型取决于响应的第一个字节(参考上文)
- 支持以下数据类型的序列化协议:简单字符串(Simple Strings,响应的第一个字节为
参考文章
